 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Self-Training to Improve Back-Translation in Low Resource Neural Machine Translation
Jun 04, 2020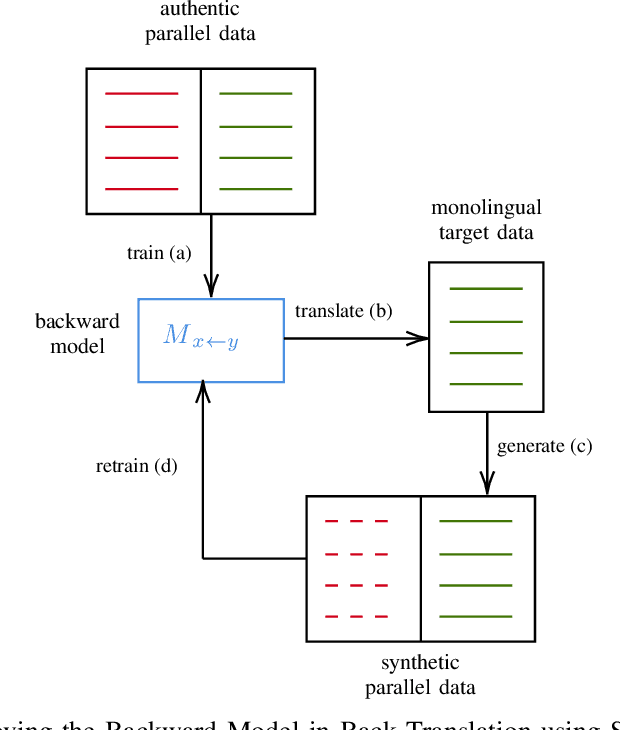
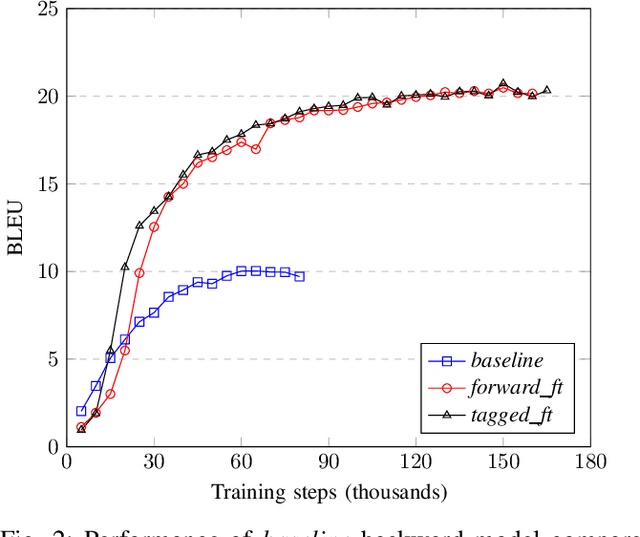


Improving neural machine translation (NMT) models using the back-translations of the monolingual target data (synthetic parallel data) is currently the state-of-the-art approach for training improved translation systems. The quality of the backward system - which is trained on the available parallel data and used for the back-translation - has been shown in many studies to affect the performance of the final NMT model. In low resource conditions, the available parallel data is usually not enough to train a backward model that can produce the qualitative synthetic data needed to train a standard translation model. This work proposes a self-training strategy where the output of the backward model is used to improve the model itself through the forward translation technique. The technique was shown to improve baseline low resource IWSLT'14 English-German and IWSLT'15 English-Vietnamese backward translation models by 11.06 and 1.5 BLEUs respectively. The synthetic data generated by the improved English-German backward model was used to train a forward model which out-performed another forward model trained using standard back-translation by 2.7 BLEU.