 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Creation and Baseline Models for Sexism Detection in Hausa
Oct 30, 2025Sexism reinforces gender inequality and social exclusion by perpetuating stereotypes, bias, and discriminatory norms. Noting how online platforms enable various forms of sexism to thrive, there is a growing need for effective sexism detection and mitigation strategies. While computational approaches to sexism detection are widespread in high-resource languages, progress remains limited in low-resource languages where limited linguistic resources and cultural differences affect how sexism is expressed and perceived. This study introduces the first Hausa sexism detection dataset, developed through community engagement, qualitative coding, and data augmentation. For cultural nuances and linguistic representation, we conducted a two-stage user study (n=66) involving native speakers to explore how sexism is defined and articulated in everyday discourse. We further experiment with both traditional machine learning classifiers and pre-trained multilingual language models and evaluating the effectiveness few-shot learning in detecting sexism in Hausa. Our findings highlight challenges in capturing cultural nuance, particularly with clarification-seeking and idiomatic expressions, and reveal a tendency for many false positives in such cases.
NaijaNLP: A Survey of Nigerian Low-Resource Languages
Feb 27, 2025With over 500 languages in Nigeria, three languages -- Hausa, Yor\`ub\'a and Igbo -- spoken by over 175 million people, account for about 60% of the spoken languages. However, these languages are categorised as low-resource due to insufficient resources to support tasks in computational linguistics. Several research efforts and initiatives have been presented, however, a coherent understanding of the state of Natural Language Processing (NLP) - from grammatical formalisation to linguistic resources that support complex tasks such as language understanding and generation is lacking. This study presents the first comprehensive review of advancements in low-resource NLP (LR-NLP) research across the three major Nigerian languages (NaijaNLP). We quantitatively assess the available linguistic resources and identify key challenges. Although a growing body of literature addresses various NLP downstream tasks in Hausa, Igbo, and Yor\`ub\'a, only about 25.1% of the reviewed studies contribute new linguistic resources. This finding highlights a persistent reliance on repurposing existing data rather than generating novel, high-quality resources. Additionally, language-specific challenges, such as the accurate representation of diacritics, remain under-explored. To advance NaijaNLP and LR-NLP more broadly, we emphasise the need for intensified efforts in resource enrichment, comprehensive annotation, and the development of open collaborative initiatives.
Detection of Offensive and Threatening Online Content in a Low Resource Language
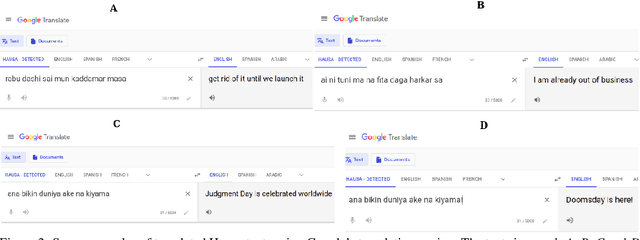
Nov 17, 2023Hausa is a major Chadic language, spoken by over 100 million people in Africa. However, from a computational linguistic perspective, it is considered a low-resource language, with limited resources to support Natural Language Processing (NLP) tasks. Online platforms often facilitate social interactions that can lead to the use of offensive and threatening language, which can go undetected due to the lack of detection systems designed for Hausa. This study aimed to address this issue by (1) conducting two user studies (n=308) to investigate cyberbullying-related issues, (2) collecting and annotating the first set of offensive and threatening datasets to support relevant downstream tasks in Hausa, (3) developing a detection system to flag offensive and threatening content, and (4) evaluating the detection system and the efficacy of the Google-based translation engine in detecting offensive and threatening terms in Hausa. We found that offensive and threatening content is quite common, particularly when discussing religion and politics. Our detection system was able to detect more than 70% of offensive and threatening content, although many of these were mistranslated by Google's translation engine. We attribute this to the subtle relationship between offensive and threatening content and idiomatic expressions in the Hausa language. We recommend that diverse stakeholders participate in understanding local conventions and demographics in order to develop a more effective detection system. These insights are essential for implementing targeted moderation strategies to create a safe and inclusive online environment.
FATE in AI: Towards Algorithmic Inclusivity and Accessibility
Jan 03, 2023One of the defining phenomena in this age is the widespread deployment of systems powered by artificial intelligence (AI) technology. With AI taking the center stage, many sections of society are being affected directly or indirectly by algorithmic decisions. Algorithmic decisions carry both economical and personal implications which have brought about the issues of fairness, accountability, transparency and ethics (FATE) in AI geared towards addressing algorithmic disparities. Ethical AI deals with incorporating moral behaviour to avoid encoding bias in AI's decisions. However, the present discourse on such critical issues is being shaped by the more economically developed countries (MEDC), which raises concerns regarding neglecting local knowledge, cultural pluralism and global fairness. This study builds upon existing research on responsible AI, with a focus on areas in the Global South considered to be under-served vis-a-vis AI. Our goal is two-fold (1) to assess FATE-related issues and the effectiveness of transparency methods and (2) to proffer useful insights and stimulate action towards bridging the accessibility and inclusivity gap in AI. Using ads data from online social networks, we designed a user study (n=43) to achieve the above goals. Among the findings from the study include: explanations about decisions reached by the AI systems tend to be vague and less informative. To bridge the accessibility and inclusivity gap, there is a need to engage with the community for the best way to integrate fairness, accountability, transparency and ethics in AI. This will help in empowering the affected community or individual to effectively probe and police the growing application of AI-powered systems.
Self-harm: detection and support on Twitter
Apr 01, 2021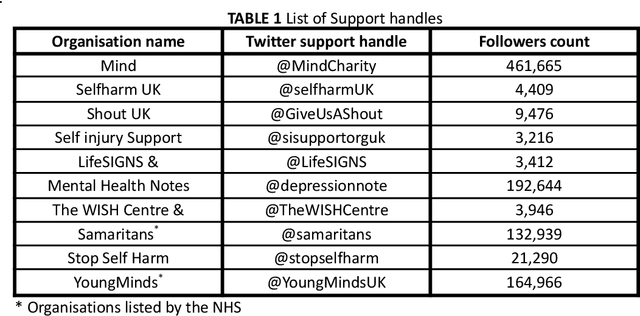
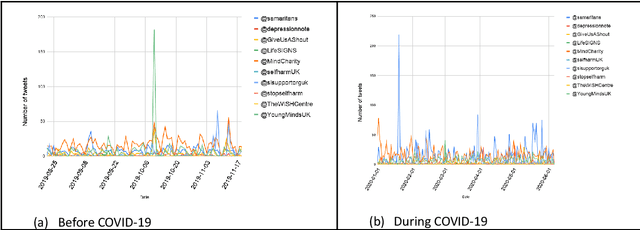
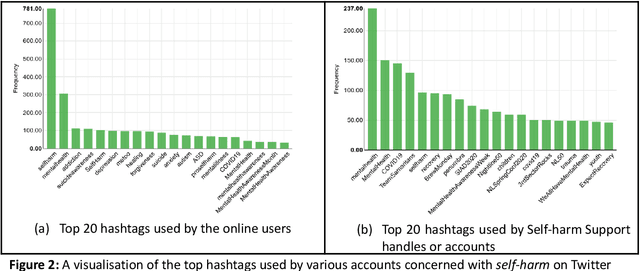
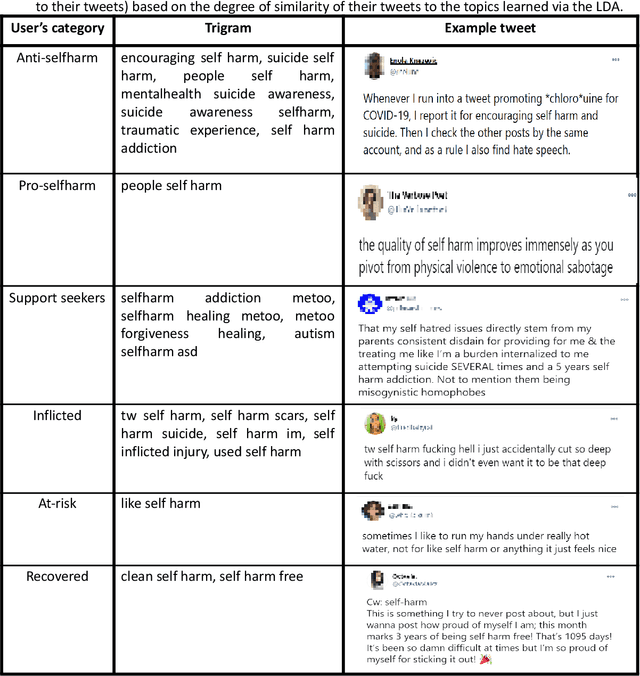
Since the advent of online social media platforms such as Twitter and Facebook, useful health-related studies have been conducted using the information posted by online participants. Personal health-related issues such as mental health, self-harm and depression have been studied because users often share their stories on such platforms. Online users resort to sharing because the empathy and support from online communities are crucial in helping the affected individuals. A preliminary analysis shows how contents related to non-suicidal self-injury (NSSI) proliferate on Twitter. Thus, we use Twitter to collect relevant data, analyse, and proffer ways of supporting users prone to NSSI behaviour. Our approach utilises a custom crawler to retrieve relevant tweets from self-reporting users and relevant organisations interested in combating self-harm. Through textual analysis, we identify six major categories of self-harming users consisting of inflicted, anti-self-harm, support seekers, recovered, pro-self-harm and at risk. The inflicted category dominates the collection. From an engagement perspective, we show how online users respond to the information posted by self-harm support organisations on Twitter. By noting the most engaged organisations, we apply a useful technique to uncover the organisations' strategy. The online participants show a strong inclination towards online posts associated with mental health related attributes. Our study is based on the premise that social media can be used as a tool to support proactive measures to ease the negative impact of self-harm. Consequently, we proffer ways to prevent potential users from engaging in self-harm and support affected users through a set of recommendations. To support further research, the dataset will be made available for interested researchers.
The first large scale collection of diverse Hausa language datasets
Feb 16, 2021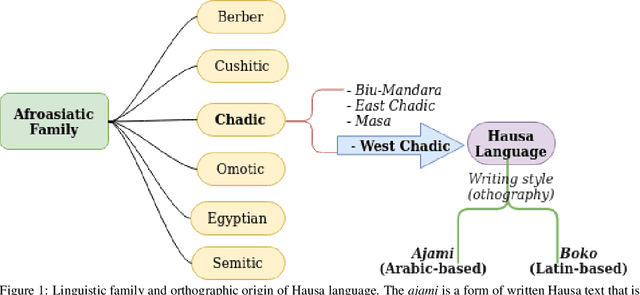


Hausa language belongs to the Afroasiatic phylum, and with more first-language speakers than any other sub-Saharan African language. With a majority of its speakers residing in the Northern and Southern areas of Nigeria and the Republic of Niger, respectively, it is estimated that over 100 million people speak the language. Hence, making it one of the most spoken Chadic language. While Hausa is considered well-studied and documented language among the sub-Saharan African languages, it is viewed as a low resource language from the perspective of natural language processing (NLP) due to limited resources to utilise in NLP-related tasks. This is common to most languages in Africa; thus, it is crucial to enrich such languages with resources that will support and speed the pace of conducting various downstream tasks to meet the demand of the modern society. While there exist useful datasets, notably from news sites and religious texts, more diversity is needed in the corpus. We provide an expansive collection of curated datasets consisting of both formal and informal forms of the language from refutable websites and online social media networks, respectively. The collection is large and more diverse than the existing corpora by providing the first and largest set of Hausa social media data posts to capture the peculiarities in the language. The collection also consists of a parallel dataset, which can be used for tasks such as machine translation with applications in areas such as the detection of spurious or inciteful online content. We describe the curation process -- from the collection, preprocessing and how to obtain the data -- and proffer some research problems that could be addressed using the data.
A multilevel clustering technique for community detection
Jan 16, 2021



A network is a composition of many communities, i.e., sets of nodes and edges with stronger relationships, with distinct and overlapping properties. Community detection is crucial for various reasons, such as serving as a functional unit of a network that captures local interactions among nodes. Communities come in various forms and types, ranging from biologically to technology-induced ones. As technology-induced communities, social media networks such as Twitter and Facebook connect a myriad of diverse users, leading to a highly connected and dynamic ecosystem. Although many algorithms have been proposed for detecting socially cohesive communities on Twitter, mining and related tasks remain challenging. This study presents a novel detection method based on a scalable framework to identify related communities in a network. We propose a multilevel clustering technique (MCT) that leverages structural and textual information to identify local communities termed microcosms. Experimental evaluation on benchmark models and datasets demonstrate the efficacy of the approach. This study contributes a new dimension for the detection of cohesive communities in social networks. The approach offers a better understanding and clarity toward describing how low-level communities evolve and behave on Twitter. From an application point of view, identifying such communities can better inform recommendation, among other benefits.
Migration and Refugee Crisis: a Critical Analysis of Online Public Perception
Jul 20, 2020



The migration rate and the level of resentments towards migrants are an important issue in modern civilisation. The infamous EU refugee crisis caught many countries unprepared, leading to sporadic and rudimentary containment measures that, in turn, led to significant public discourse. Decades of offline data collected via traditional survey methods have been utilised earlier to understand public opinion to foster peaceful coexistence. Capturing and understanding online public opinion via social media is crucial towards a joint strategic regulation spanning safety, rights of migrants and cordial integration for economic prosperity. We present a analysis of opinions on migrants and refugees expressed by the users of a very popular social platform, Twitter. We analyse sentiment and the associated context of expressions in a vast collection of tweets related to the EU refugee crisis. Our study reveals a marginally higher proportion of negative sentiments vis-a-vis migrants and a large proportion of the negative sentiments is more reflected among the ordinary users. Users with many followers and non-governmental organisations (NGO) tend to tweet favourably about the topic, offsetting the distribution of negative sentiment. We opine that they can be encouraged to be more proactive in neutralising negative attitudes that may arise concerning similar incidences.
Introduction to intelligent computing unit 1
Nov 15, 2017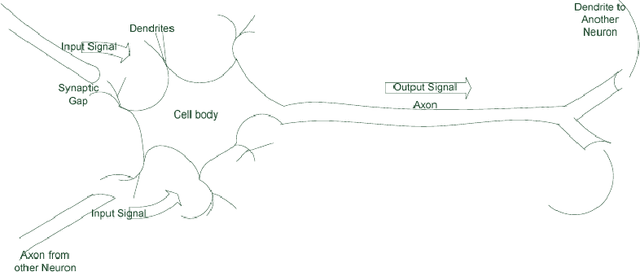
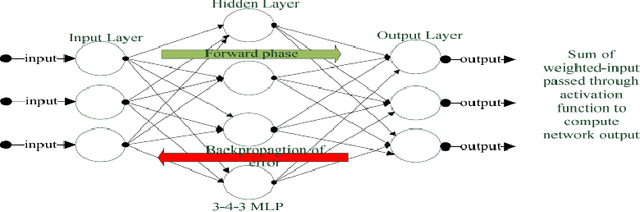
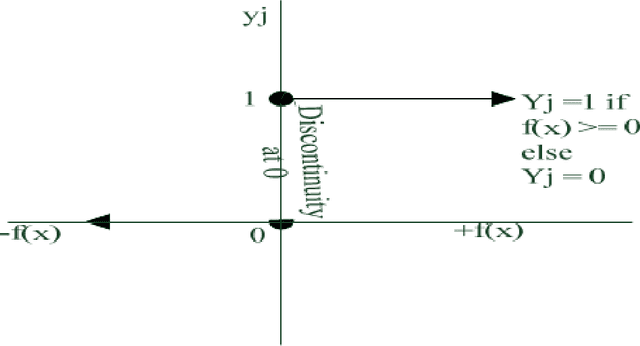
This brief note highlights some basic concepts required toward understanding the evolution of machine learning and deep learning models. The note starts with an overview of artificial intelligence and its relationship to biological neuron that ultimately led to the evolution of todays intelligent models.