 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023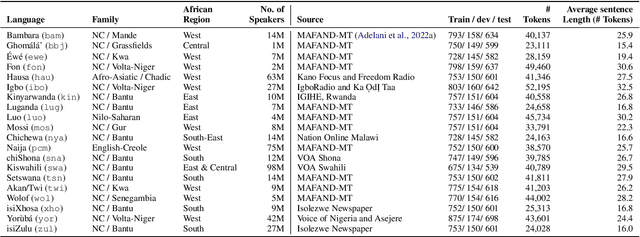
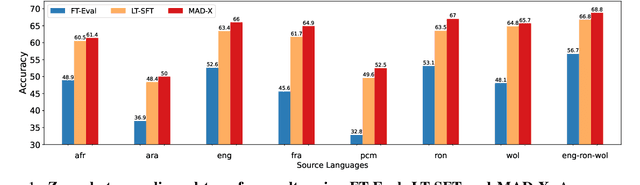
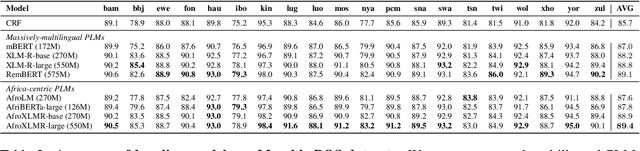
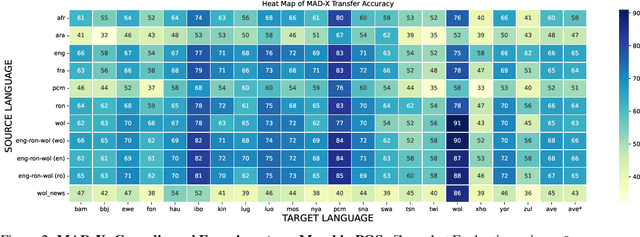
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
HausaNLP at SemEval-2023 Task 10: Transfer Learning, Synthetic Data and Side-Information for Multi-Level Sexism Classification
Apr 28, 2023We present the findings of our participation in the SemEval-2023 Task 10: Explainable Detection of Online Sexism (EDOS) task, a shared task on offensive language (sexism) detection on English Gab and Reddit dataset. We investigated the effects of transferring two language models: XLM-T (sentiment classification) and HateBERT (same domain -- Reddit) for multi-level classification into Sexist or not Sexist, and other subsequent sub-classifications of the sexist data. We also use synthetic classification of unlabelled dataset and intermediary class information to maximize the performance of our models. We submitted a system in Task A, and it ranked 49th with F1-score of 0.82. This result showed to be competitive as it only under-performed the best system by 0.052% F1-score.
HausaNLP at SemEval-2023 Task 12: Leveraging African Low Resource TweetData for Sentiment Analysis
Apr 26, 2023We present the findings of SemEval-2023 Task 12, a shared task on sentiment analysis for low-resource African languages using Twitter dataset. The task featured three subtasks; subtask A is monolingual sentiment classification with 12 tracks which are all monolingual languages, subtask B is multilingual sentiment classification using the tracks in subtask A and subtask C is a zero-shot sentiment classification. We present the results and findings of subtask A, subtask B and subtask C. We also release the code on github. Our goal is to leverage low-resource tweet data using pre-trained Afro-xlmr-large, AfriBERTa-Large, Bert-base-arabic-camelbert-da-sentiment (Arabic-camelbert), Multilingual-BERT (mBERT) and BERT models for sentiment analysis of 14 African languages. The datasets for these subtasks consists of a gold standard multi-class labeled Twitter datasets from these languages. Our results demonstrate that Afro-xlmr-large model performed better compared to the other models in most of the languages datasets. Similarly, Nigerian languages: Hausa, Igbo, and Yoruba achieved better performance compared to other languages and this can be attributed to the higher volume of data present in the languages.