 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Synthetic Real-World Degradations for Blind Video Super Resolution
May 04, 2023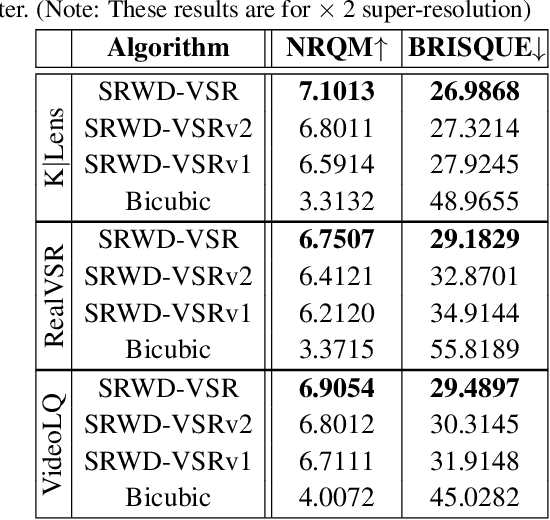
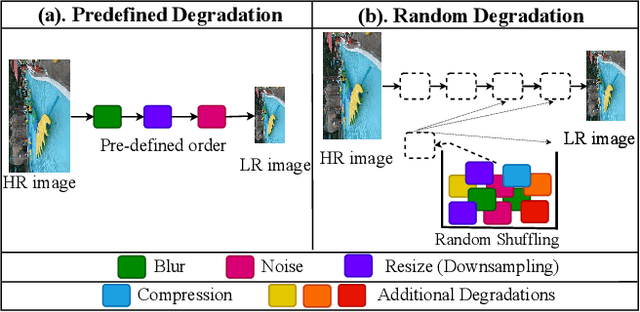
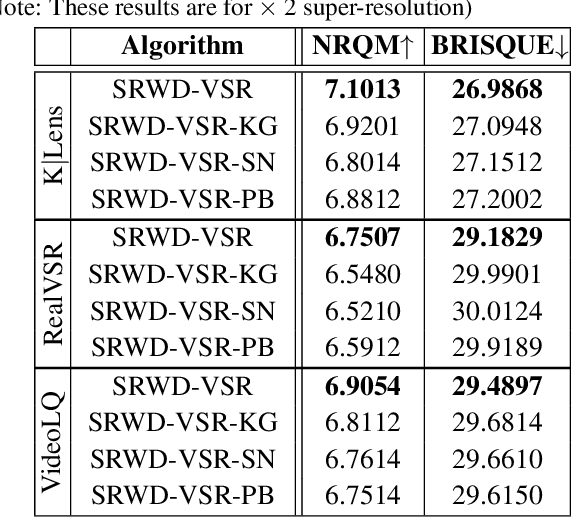
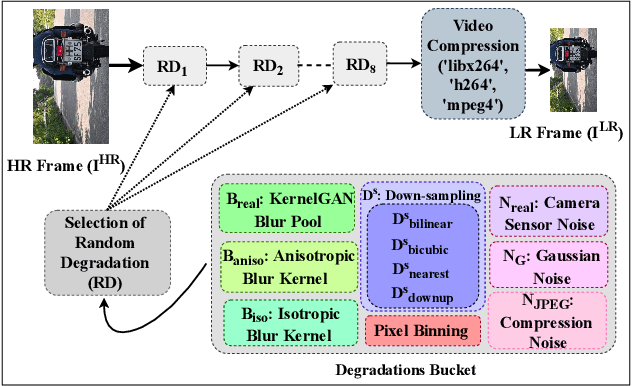
Video super-resolution (VSR) techniques, especially deep-learning-based algorithms, have drastically improved over the last few years and shown impressive performance on synthetic data. However, their performance on real-world video data suffers because of the complexity of real-world degradations and misaligned video frames. Since obtaining a synthetic dataset consisting of low-resolution (LR) and high-resolution (HR) frames are easier than obtaining real-world LR and HR images, in this paper, we propose synthesizing real-world degradations on synthetic training datasets. The proposed synthetic real-world degradations (SRWD) include a combination of the blur, noise, downsampling, pixel binning, and image and video compression artifacts. We then propose using a random shuffling-based strategy to simulate these degradations on the training datasets and train a single end-to-end deep neural network (DNN) on the proposed larger variation of realistic synthesized training data. Our quantitative and qualitative comparative analysis shows that the proposed training strategy using diverse realistic degradations improves the performance by 7.1 % in terms of NRQM compared to RealBasicVSR and by 3.34 % compared to BSRGAN on the VideoLQ dataset. We also introduce a new dataset that contains high-resolution real-world videos that can serve as a common ground for bench-marking.
Edge-aware Consistent Stereo Video Depth Estimation
May 04, 2023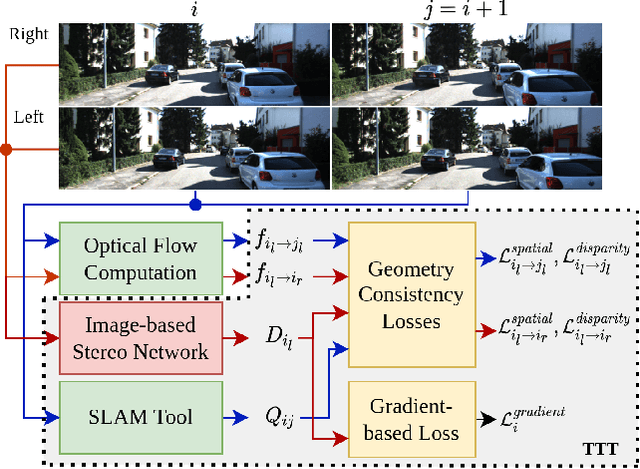
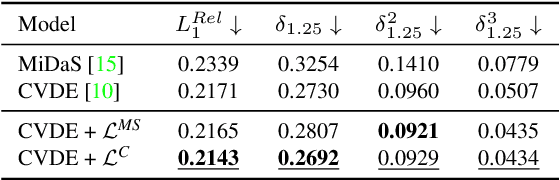


Video depth estimation is crucial in various applications, such as scene reconstruction and augmented reality. In contrast to the naive method of estimating depths from images, a more sophisticated approach uses temporal information, thereby eliminating flickering and geometrical inconsistencies. We propose a consistent method for dense video depth estimation; however, unlike the existing monocular methods, ours relates to stereo videos. This technique overcomes the limitations arising from the monocular input. As a benefit of using stereo inputs, a left-right consistency loss is introduced to improve the performance. Besides, we use SLAM-based camera pose estimation in the process. To address the problem of depth blurriness during test-time training (TTT), we present an edge-preserving loss function that improves the visibility of fine details while preserving geometrical consistency. We show that our edge-aware stereo video model can accurately estimate the dense depth maps.
High-Resolution Synthetic RGB-D Datasets for Monocular Depth Estimation
May 02, 2023
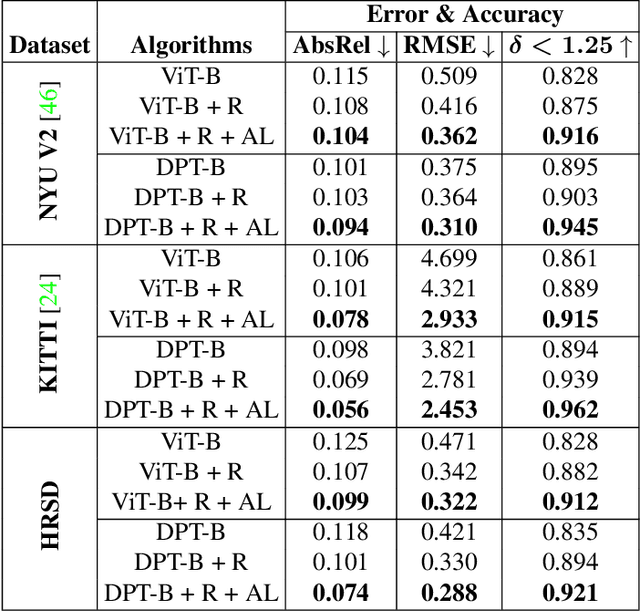

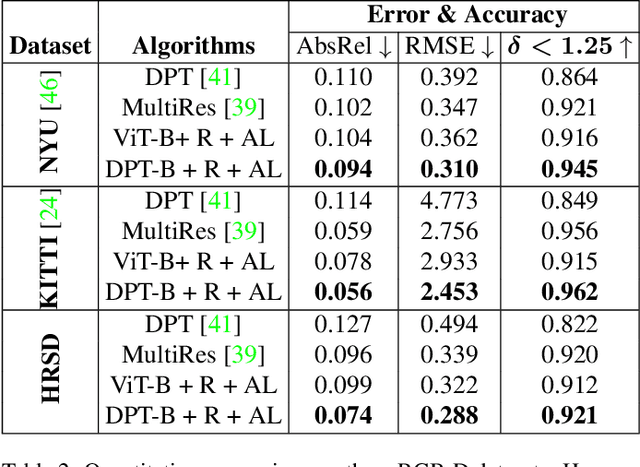
Accurate depth maps are essential in various applications, such as autonomous driving, scene reconstruction, point-cloud creation, etc. However, monocular-depth estimation (MDE) algorithms often fail to provide enough texture & sharpness, and also are inconsistent for homogeneous scenes. These algorithms mostly use CNN or vision transformer-based architectures requiring large datasets for supervised training. But, MDE algorithms trained on available depth datasets do not generalize well and hence fail to perform accurately in diverse real-world scenes. Moreover, the ground-truth depth maps are either lower resolution or sparse leading to relatively inconsistent depth maps. In general, acquiring a high-resolution ground truth dataset with pixel-level precision for accurate depth prediction is an expensive, and time-consuming challenge. In this paper, we generate a high-resolution synthetic depth dataset (HRSD) of dimension 1920 X 1080 from Grand Theft Auto (GTA-V), which contains 100,000 color images and corresponding dense ground truth depth maps. The generated datasets are diverse and have scenes from indoors to outdoors, from homogeneous surfaces to textures. For experiments and analysis, we train the DPT algorithm, a state-of-the-art transformer-based MDE algorithm on the proposed synthetic dataset, which significantly increases the accuracy of depth maps on different scenes by 9 %. Since the synthetic datasets are of higher resolution, we propose adding a feature extraction module in the transformer encoder and incorporating an attention-based loss, further improving the accuracy by 15 %.
Leveraging Multi-view Data for Improved Detection Performance: An Industrial Use Case
Apr 17, 2023


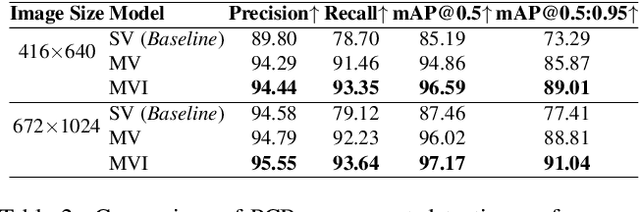
Printed circuit boards (PCBs) are essential components of electronic devices, and ensuring their quality is crucial in their production. However, the vast variety of components and PCBs manufactured by different companies makes it challenging to adapt to production lines with speed demands. To address this challenge, we present a multi-view object detection framework that offers a fast and precise solution. We introduce a novel multi-view dataset with semi-automatic ground-truth data, which results in significant labeling resource savings. Labeling PCB boards for object detection is a challenging task due to the high density of components and the small size of the objects, which makes it difficult to identify and label them accurately. By training an object detector model with multi-view data, we achieve improved performance over single-view images. To further enhance the accuracy, we develop a multi-view inference method that aggregates results from different viewpoints. Our experiments demonstrate a 15% improvement in mAP for detecting components that range in size from 0.5 to 27.0 mm.