 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Synthetic RGB-D Datasets for Monocular Depth Estimation
May 02, 2023
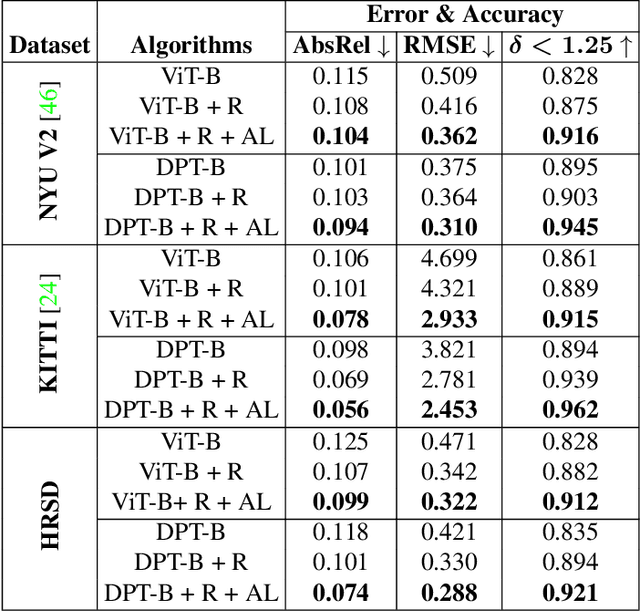

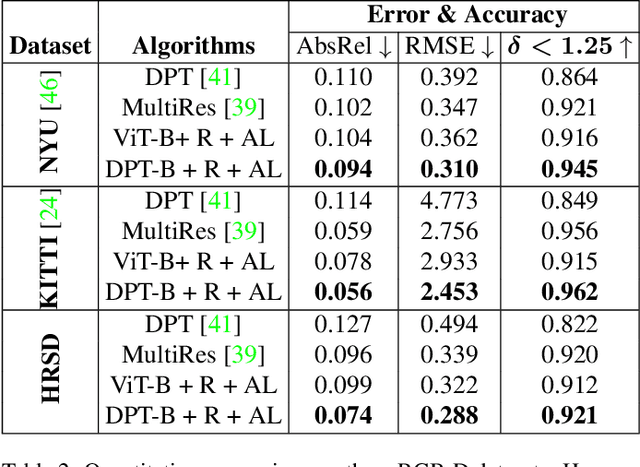
Accurate depth maps are essential in various applications, such as autonomous driving, scene reconstruction, point-cloud creation, etc. However, monocular-depth estimation (MDE) algorithms often fail to provide enough texture & sharpness, and also are inconsistent for homogeneous scenes. These algorithms mostly use CNN or vision transformer-based architectures requiring large datasets for supervised training. But, MDE algorithms trained on available depth datasets do not generalize well and hence fail to perform accurately in diverse real-world scenes. Moreover, the ground-truth depth maps are either lower resolution or sparse leading to relatively inconsistent depth maps. In general, acquiring a high-resolution ground truth dataset with pixel-level precision for accurate depth prediction is an expensive, and time-consuming challenge. In this paper, we generate a high-resolution synthetic depth dataset (HRSD) of dimension 1920 X 1080 from Grand Theft Auto (GTA-V), which contains 100,000 color images and corresponding dense ground truth depth maps. The generated datasets are diverse and have scenes from indoors to outdoors, from homogeneous surfaces to textures. For experiments and analysis, we train the DPT algorithm, a state-of-the-art transformer-based MDE algorithm on the proposed synthetic dataset, which significantly increases the accuracy of depth maps on different scenes by 9 %. Since the synthetic datasets are of higher resolution, we propose adding a feature extraction module in the transformer encoder and incorporating an attention-based loss, further improving the accuracy by 15 %.