 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-aware Consistent Stereo Video Depth Estimation
May 04, 2023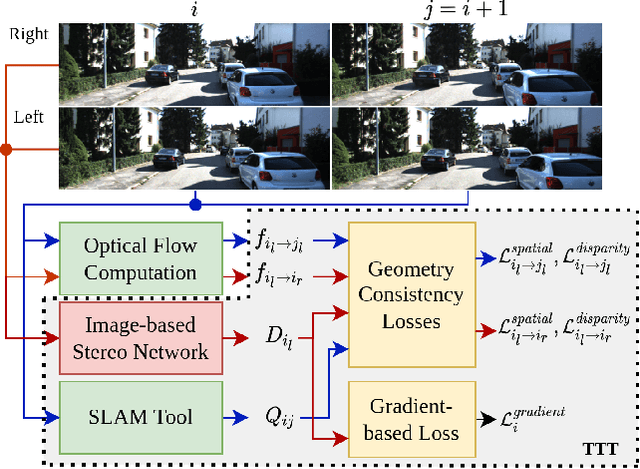
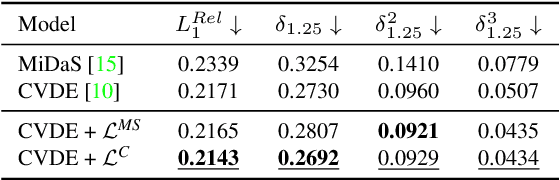


Video depth estimation is crucial in various applications, such as scene reconstruction and augmented reality. In contrast to the naive method of estimating depths from images, a more sophisticated approach uses temporal information, thereby eliminating flickering and geometrical inconsistencies. We propose a consistent method for dense video depth estimation; however, unlike the existing monocular methods, ours relates to stereo videos. This technique overcomes the limitations arising from the monocular input. As a benefit of using stereo inputs, a left-right consistency loss is introduced to improve the performance. Besides, we use SLAM-based camera pose estimation in the process. To address the problem of depth blurriness during test-time training (TTT), we present an edge-preserving loss function that improves the visibility of fine details while preserving geometrical consistency. We show that our edge-aware stereo video model can accurately estimate the dense depth maps.
Leveraging Multi-view Data for Improved Detection Performance: An Industrial Use Case
Apr 17, 2023


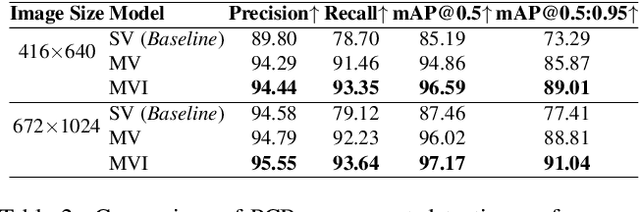
Printed circuit boards (PCBs) are essential components of electronic devices, and ensuring their quality is crucial in their production. However, the vast variety of components and PCBs manufactured by different companies makes it challenging to adapt to production lines with speed demands. To address this challenge, we present a multi-view object detection framework that offers a fast and precise solution. We introduce a novel multi-view dataset with semi-automatic ground-truth data, which results in significant labeling resource savings. Labeling PCB boards for object detection is a challenging task due to the high density of components and the small size of the objects, which makes it difficult to identify and label them accurately. By training an object detector model with multi-view data, we achieve improved performance over single-view images. To further enhance the accuracy, we develop a multi-view inference method that aggregates results from different viewpoints. Our experiments demonstrate a 15% improvement in mAP for detecting components that range in size from 0.5 to 27.0 mm.
TriStereoNet: A Trinocular Framework for Multi-baseline Disparity Estimation
Nov 24, 2021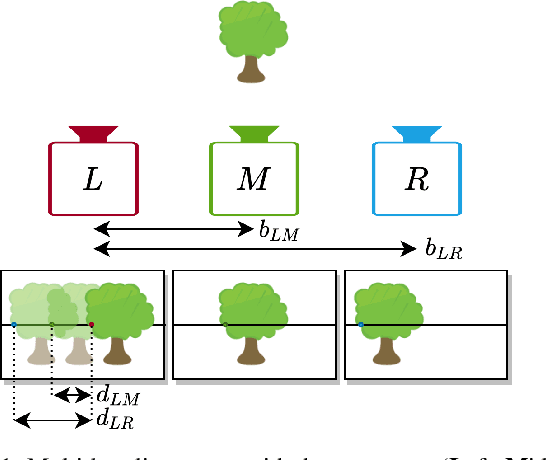



Stereo vision is an effective technique for depth estimation with broad applicability in autonomous urban and highway driving. While various deep learning-based approaches have been developed for stereo, the input data from a binocular setup with a fixed baseline are limited. Addressing such a problem, we present an end-to-end network for processing the data from a trinocular setup, which is a combination of a narrow and a wide stereo pair. In this design, two pairs of binocular data with a common reference image are treated with shared weights of the network and a mid-level fusion. We also propose a Guided Addition method for merging the 4D data of the two baselines. Additionally, an iterative sequential self-supervised and supervised learning on real and synthetic datasets is presented, making the training of the trinocular system practical with no need to ground-truth data of the real dataset. Experimental results demonstrate that the trinocular disparity network surpasses the scenario where individual pairs are fed into a similar architecture. Code and dataset: https://github.com/cogsys-tuebingen/tristereonet.
Separable Convolutions for Optimizing 3D Stereo Networks
Aug 23, 2021



Deep learning based 3D stereo networks give superior performance compared to 2D networks and conventional stereo methods. However, this improvement in the performance comes at the cost of increased computational complexity, thus making these networks non-practical for the real-world applications. Specifically, these networks use 3D convolutions as a major work horse to refine and regress disparities. In this work first, we show that these 3D convolutions in stereo networks consume up to 94% of overall network operations and act as a major bottleneck. Next, we propose a set of "plug-&-run" separable convolutions to reduce the number of parameters and operations. When integrated with the existing state of the art stereo networks, these convolutions lead up to 7x reduction in number of operations and up to 3.5x reduction in parameters without compromising their performance. In fact these convolutions lead to improvement in their performance in the majority of cases.
MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching
Aug 22, 2021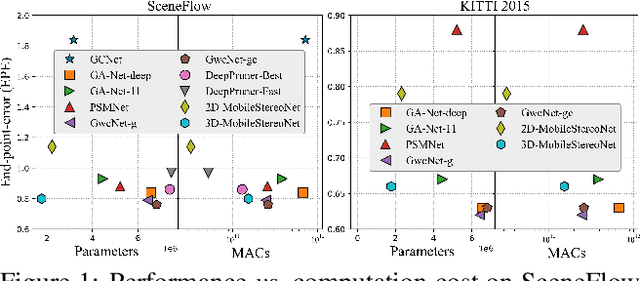
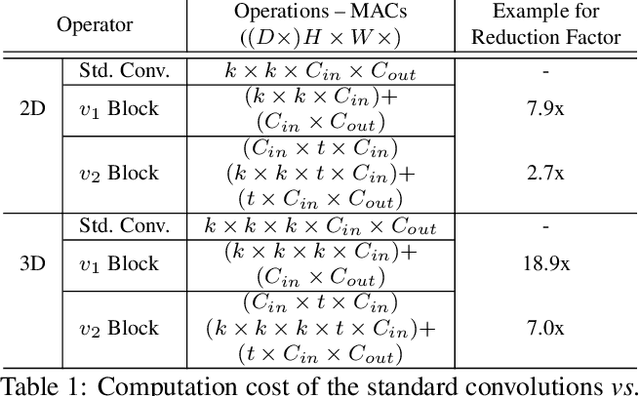
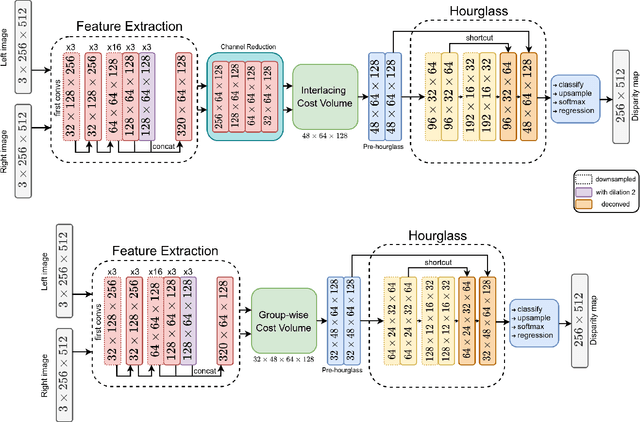

Recent methods in stereo matching have continuously improved the accuracy using deep models. This gain, however, is attained with a high increase in computation cost, such that the network may not fit even on a moderate GPU. This issue raises problems when the model needs to be deployed on resource-limited devices. For this, we propose two light models for stereo vision with reduced complexity and without sacrificing accuracy. Depending on the dimension of cost volume, we design a 2D and a 3D model with encoder-decoders built from 2D and 3D convolutions, respectively. To this end, we leverage 2D MobileNet blocks and extend them to 3D for stereo vision application. Besides, a new cost volume is proposed to boost the accuracy of the 2D model, making it performing close to 3D networks. Experiments show that the proposed 2D/3D networks effectively reduce the computational expense (27%/95% and 72%/38% fewer parameters/operations in 2D and 3D models, respectively) while upholding the accuracy. Our code is available at https://github.com/cogsys-tuebingen/mobilestereonet.
Object detection and Autoencoder-based 6D pose estimation for highly cluttered Bin Picking
Jun 15, 2021
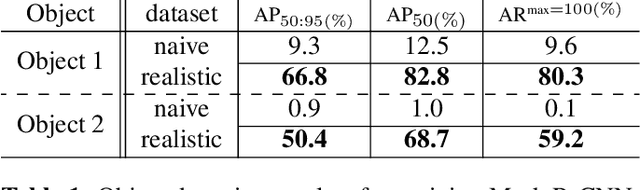

Bin picking is a core problem in industrial environments and robotics, with its main module as 6D pose estimation. However, industrial depth sensors have a lack of accuracy when it comes to small objects. Therefore, we propose a framework for pose estimation in highly cluttered scenes with small objects, which mainly relies on RGB data and makes use of depth information only for pose refinement. In this work, we compare synthetic data generation approaches for object detection and pose estimation and introduce a pose filtering algorithm that determines the most accurate estimated poses. We will make our