 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Stereo Networks for Performant and Efficient Leaner Networks
Mar 24, 2025



Knowledge distillation has been quite popular in vision for tasks like classification and segmentation however not much work has been done for distilling state-of-the-art stereo matching methods despite their range of applications. One of the reasons for its lack of use in stereo matching networks is due to the inherent complexity of these networks, where a typical network is composed of multiple two- and three-dimensional modules. In this work, we systematically combine the insights from state-of-the-art stereo methods with general knowledge-distillation techniques to develop a joint framework for stereo networks distillation with competitive results and faster inference. Moreover, we show, via a detailed empirical analysis, that distilling knowledge from the stereo network requires careful design of the complete distillation pipeline starting from backbone to the right selection of distillation points and corresponding loss functions. This results in the student networks that are not only leaner and faster but give excellent performance . For instance, our student network while performing better than the performance oriented methods like PSMNet [1], CFNet [2], and LEAStereo [3]) on benchmark SceneFlow dataset, is 8x, 5x, and 8x faster respectively. Furthermore, compared to speed oriented methods having inference time less than 100ms, our student networks perform better than all the tested methods. In addition, our student network also shows better generalization capabilities when tested on unseen datasets like ETH3D and Middlebury.
LeanStereo: A Leaner Backbone based Stereo Network
Mar 24, 2025Recently, end-to-end deep networks based stereo matching methods, mainly because of their performance, have gained popularity. However, this improvement in performance comes at the cost of increased computational and memory bandwidth requirements, thus necessitating specialized hardware (GPUs); even then, these methods have large inference times compared to classical methods. This limits their applicability in real-world applications. Although we desire high accuracy stereo methods albeit with reasonable inference time. To this end, we propose a fast end-to-end stereo matching method. Majority of this speedup comes from integrating a leaner backbone. To recover the performance lost because of a leaner backbone, we propose to use learned attention weights based cost volume combined with LogL1 loss for stereo matching. Using LogL1 loss not only improves the overall performance of the proposed network but also leads to faster convergence. We do a detailed empirical evaluation of different design choices and show that our method requires 4x less operations and is also about 9 to 14x faster compared to the state of the art methods like ACVNet [1], LEAStereo [2] and CFNet [3] while giving comparable performance.
* 8 pages, 4 figures
MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching
Aug 22, 2021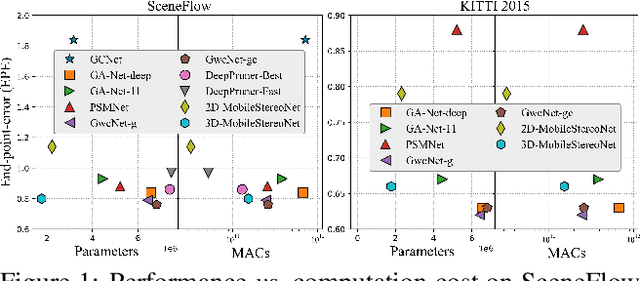
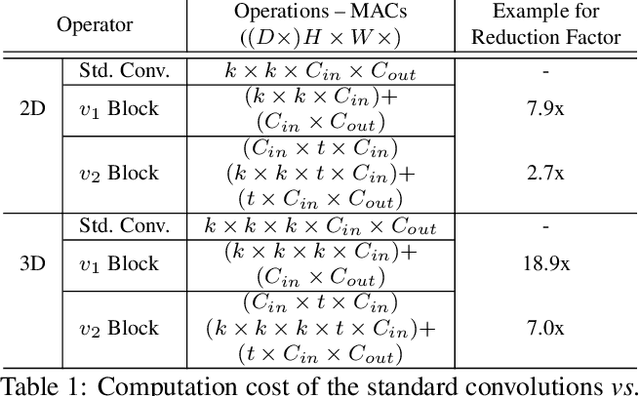
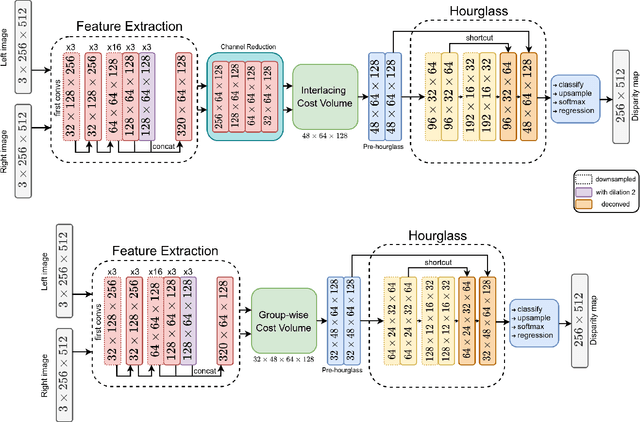

Recent methods in stereo matching have continuously improved the accuracy using deep models. This gain, however, is attained with a high increase in computation cost, such that the network may not fit even on a moderate GPU. This issue raises problems when the model needs to be deployed on resource-limited devices. For this, we propose two light models for stereo vision with reduced complexity and without sacrificing accuracy. Depending on the dimension of cost volume, we design a 2D and a 3D model with encoder-decoders built from 2D and 3D convolutions, respectively. To this end, we leverage 2D MobileNet blocks and extend them to 3D for stereo vision application. Besides, a new cost volume is proposed to boost the accuracy of the 2D model, making it performing close to 3D networks. Experiments show that the proposed 2D/3D networks effectively reduce the computational expense (27%/95% and 72%/38% fewer parameters/operations in 2D and 3D models, respectively) while upholding the accuracy. Our code is available at https://github.com/cogsys-tuebingen/mobilestereonet.