 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Spring Neural ODEs for Link Sign Prediction
Dec 18, 2024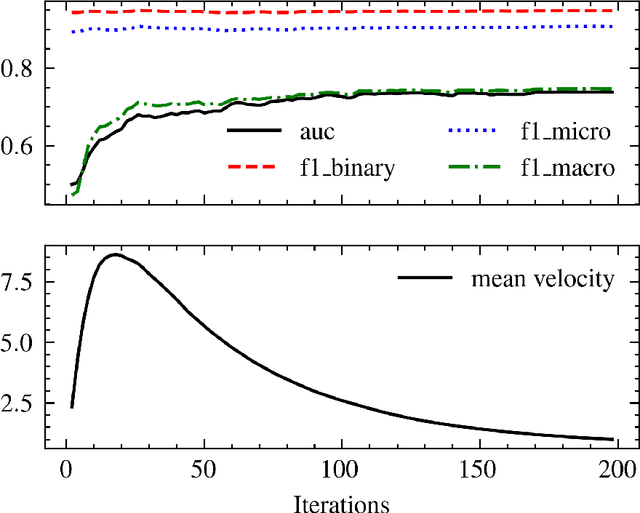
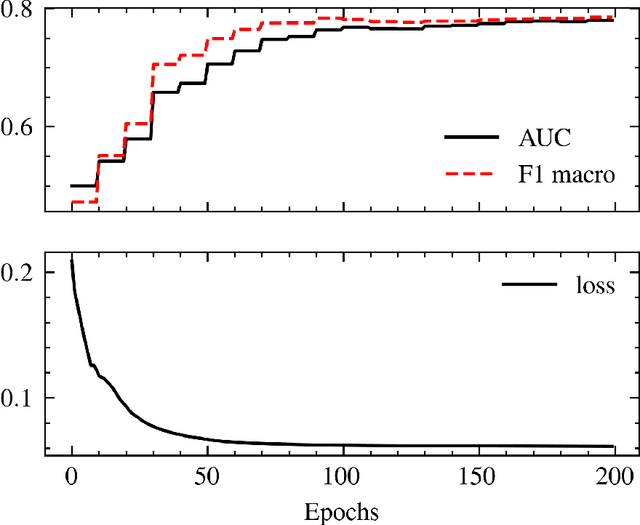
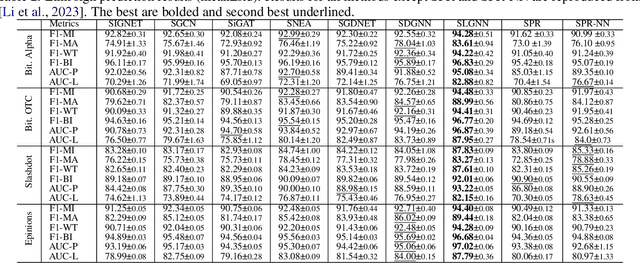
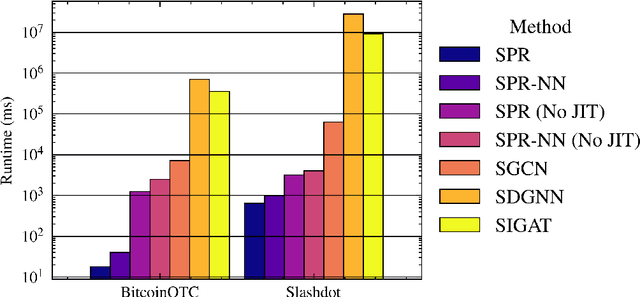
Signed graphs allow for encoding positive and negative relations between nodes and are used to model various online activities. Node representation learning for signed graphs is a well-studied task with important applications such as sign prediction. While the size of datasets is ever-increasing, recent methods often sacrifice scalability for accuracy. We propose a novel message-passing layer architecture called Graph Spring Network (GSN) modeled after spring forces. We combine it with a Graph Neural Ordinary Differential Equations (ODEs) formalism to optimize the system dynamics in embedding space to solve a downstream prediction task. Once the dynamics is learned, embedding generation for novel datasets is done by solving the ODEs in time using a numerical integration scheme. Our GSN layer leverages the fast-to-compute edge vector directions and learnable scalar functions that only depend on nodes' distances in latent space to compute the nodes' positions. Conversely, Graph Convolution and Graph Attention Network layers rely on learnable vector functions that require the full positions of input nodes in latent space. We propose a specific implementation called Spring-Neural-Network (SPR-NN) using a set of small neural networks mimicking attracting and repulsing spring forces that we train for link sign prediction. Experiments show that our method achieves accuracy close to the state-of-the-art methods with node generation time speedup factors of up to 28,000 on large graphs.
Lost in Translation -- Multilingual Misinformation and its Evolution
Oct 27, 2023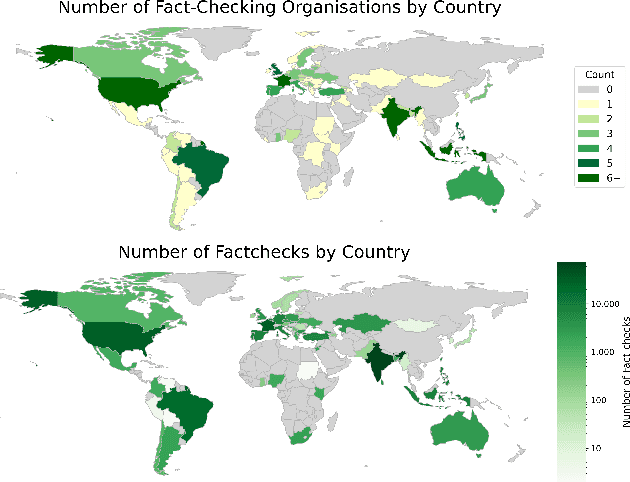

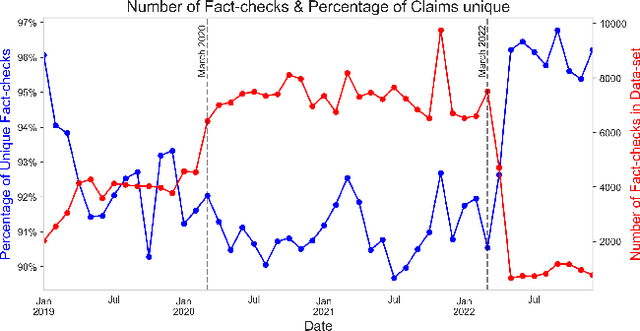

Misinformation and disinformation are growing threats in the digital age, spreading rapidly across languages and borders. This paper investigates the prevalence and dynamics of multilingual misinformation through an analysis of over 250,000 unique fact-checks spanning 95 languages. First, we find that while the majority of misinformation claims are only fact-checked once, 11.7%, corresponding to more than 21,000 claims, are checked multiple times. Using fact-checks as a proxy for the spread of misinformation, we find 33% of repeated claims cross linguistic boundaries, suggesting that some misinformation permeates language barriers. However, spreading patterns exhibit strong homophily, with misinformation more likely to spread within the same language. To study the evolution of claims over time and mutations across languages, we represent fact-checks with multilingual sentence embeddings and cluster semantically similar claims. We analyze the connected components and shortest paths connecting different versions of a claim finding that claims gradually drift over time and undergo greater alteration when traversing languages. Overall, this novel investigation of multilingual misinformation provides key insights. It quantifies redundant fact-checking efforts, establishes that some claims diffuse across languages, measures linguistic homophily, and models the temporal and cross-lingual evolution of claims. The findings advocate for expanded information sharing between fact-checkers globally while underscoring the importance of localized verification.
The Perils & Promises of Fact-checking with Large Language Models
Oct 20, 2023



Autonomous fact-checking, using machine learning to verify claims, has grown vital as misinformation spreads beyond human fact-checking capacity. Large Language Models (LLMs) like GPT-4 are increasingly trusted to verify information and write academic papers, lawsuits, and news articles, emphasizing their role in discerning truth from falsehood and the importance of being able to verify their outputs. Here, we evaluate the use of LLM agents in fact-checking by having them phrase queries, retrieve contextual data, and make decisions. Importantly, in our framework, agents explain their reasoning and cite the relevant sources from the retrieved context. Our results show the enhanced prowess of LLMs when equipped with contextual information. GPT-4 outperforms GPT-3, but accuracy varies based on query language and claim veracity. While LLMs show promise in fact-checking, caution is essential due to inconsistent accuracy. Our investigation calls for further research, fostering a deeper comprehension of when agents succeed and when they fail.