 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Similarity Matrix based CNN Filter Pruning
Nov 03, 2022



In recent years, most of the deep learning solutions are targeted to be deployed in mobile devices. This makes the need for development of lightweight models all the more imminent. Another solution is to optimize and prune regular deep learning models. In this paper, we tackle the problem of CNN model pruning with the help of Self-Similarity Matrix (SSM) computed from the 2D CNN filters. We propose two novel algorithms to rank and prune redundant filters which contribute similar activation maps to the output. One of the key features of our method is that there is no need of finetuning after training the model. Both the training and pruning process is completed simultaneously. We benchmark our method on two of the most popular CNN models - ResNet and VGG and record their performance on the CIFAR-10 dataset.
Language Detection Engine for Multilingual Texting on Mobile Devices
Jan 07, 2021

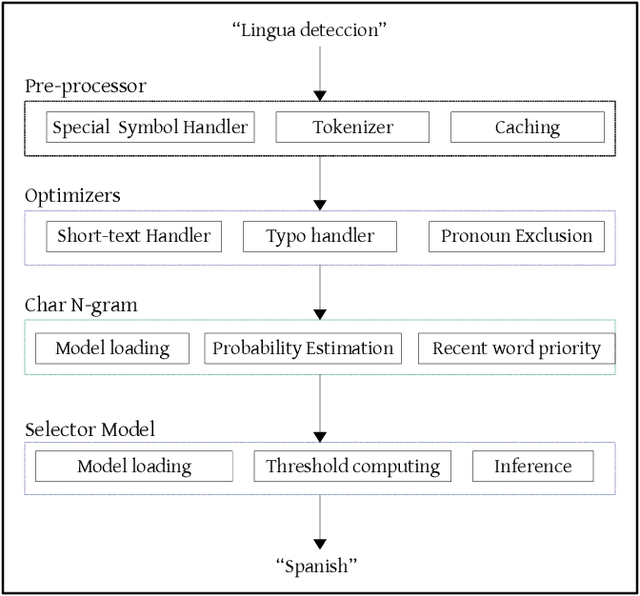

More than 2 billion mobile users worldwide type in multiple languages in the soft keyboard. On a monolingual keyboard, 38% of falsely auto-corrected words are valid in another language. This can be easily avoided by detecting the language of typed words and then validating it in its respective language. Language detection is a well-known problem in natural language processing. In this paper, we present a fast, light-weight and accurate Language Detection Engine (LDE) for multilingual typing that dynamically adapts to user intended language in real-time. We propose a novel approach where the fusion of character N-gram model and logistic regression based selector model is used to identify the language. Additionally, we present a unique method of reducing the inference time significantly by parameter reduction technique. We also discuss various optimizations fabricated across LDE to resolve ambiguity in input text among the languages with the same character pattern. Our method demonstrates an average accuracy of 94.5% for Indian languages in Latin script and that of 98% for European languages on the code-switched data. This model outperforms fastText by 60.39% and ML-Kit by 23.67% in F1 score for European languages. LDE is faster on mobile device with an average inference time of 25.91 microseconds.
* 2020 IEEE 14th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/9031474
Real-Time Optimized N-gram For Mobile Devices
Jan 07, 2021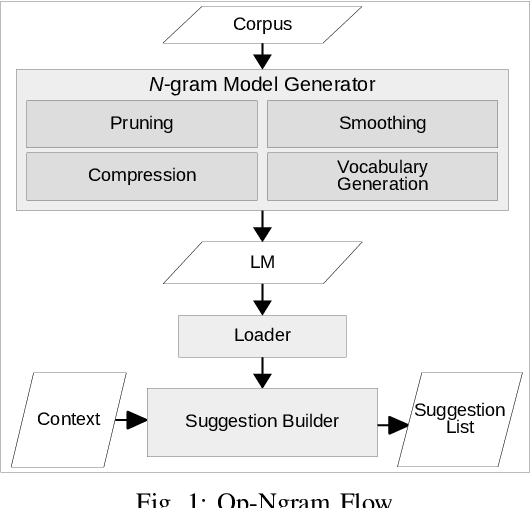
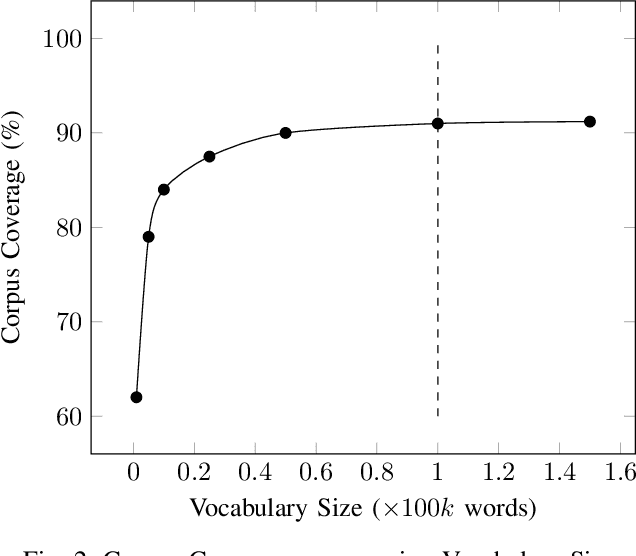
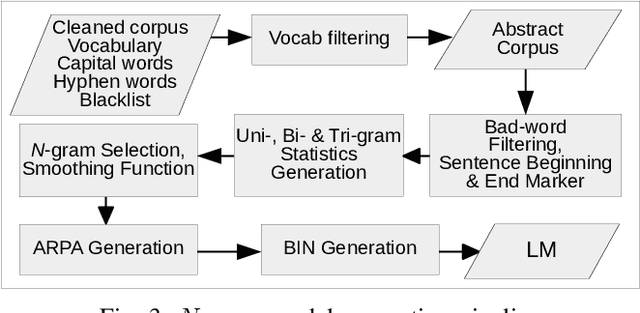

With the increasing number of mobile devices, there has been continuous research on generating optimized Language Models (LMs) for soft keyboard. In spite of advances in this domain, building a single LM for low-end feature phones as well as high-end smartphones is still a pressing need. Hence, we propose a novel technique, Optimized N-gram (Op-Ngram), an end-to-end N-gram pipeline that utilises mobile resources efficiently for faster Word Completion (WC) and Next Word Prediction (NWP). Op-Ngram applies Stupid Backoff and pruning strategies to generate a light-weight model. The LM loading time on mobile is linear with respect to model size. We observed that Op-Ngram gives 37% improvement in Language Model (LM)-ROM size, 76% in LM-RAM size, 88% in loading time and 89% in average suggestion time as compared to SORTED array variant of BerkeleyLM. Moreover, our method shows significant performance improvement over KenLM as well.
* 2019 IEEE 13th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/8665639
edATLAS: An Efficient Disambiguation Algorithm for Texting in Languages with Abugida Scripts
Jan 05, 2021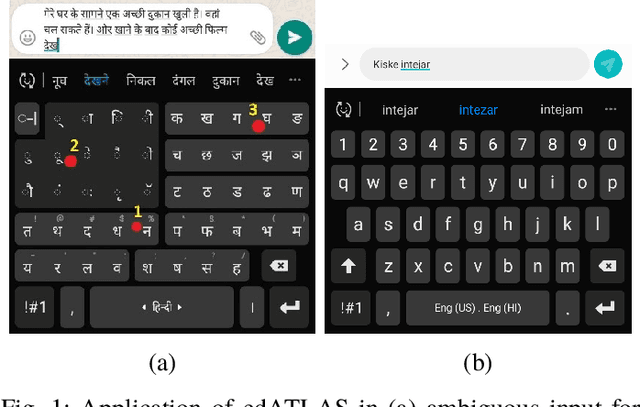
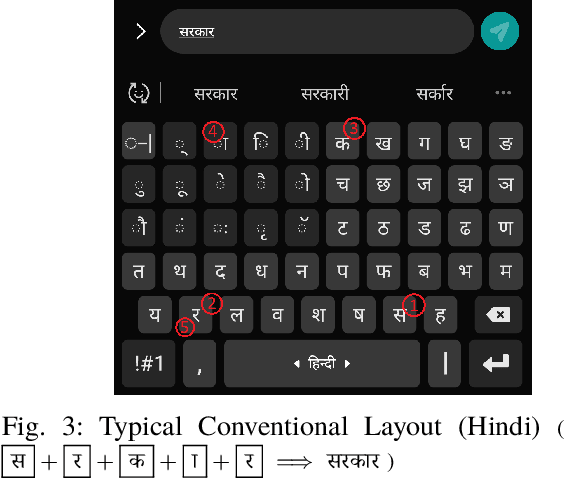
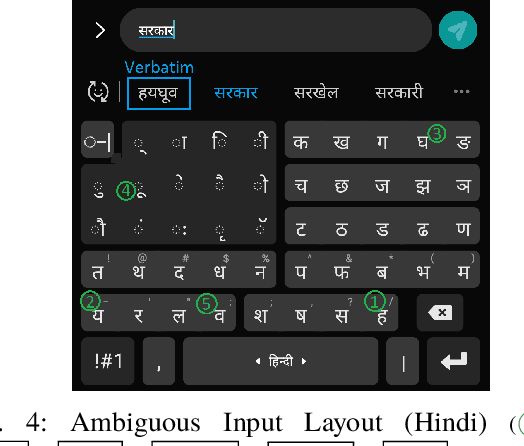
Abugida refers to a phonogram writing system where each syllable is represented using a single consonant or typographic ligature, along with a default vowel or optional diacritic(s) to denote other vowels. However, texting in these languages has some unique challenges in spite of the advent of devices with soft keyboard supporting custom key layouts. The number of characters in these languages is large enough to require characters to be spread over multiple views in the layout. Having to switch between views many times to type a single word hinders the natural thought process. This prevents popular usage of native keyboard layouts. On the other hand, supporting romanized scripts (native words transcribed using Latin characters) with language model based suggestions is also set back by the lack of uniform romanization rules. To this end, we propose a disambiguation algorithm and showcase its usefulness in two novel mutually non-exclusive input methods for languages natively using the abugida writing system: (a) disambiguation of ambiguous input for abugida scripts, and (b) disambiguation of word variants in romanized scripts. We benchmark these approaches using public datasets, and show an improvement in typing speed by 19.49%, 25.13%, and 14.89%, in Hindi, Bengali, and Thai, respectively, using Ambiguous Input, owing to the human ease of locating keys combined with the efficiency of our inference method. Our Word Variant Disambiguation (WDA) maps valid variants of romanized words, previously treated as Out-of-Vocab, to a vocabulary of 100k words with high accuracy, leading to an increase in Error Correction F1 score by 10.03% and Next Word Prediction (NWP) by 62.50% on average.