 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Detection Engine for Multilingual Texting on Mobile Devices
Jan 07, 2021

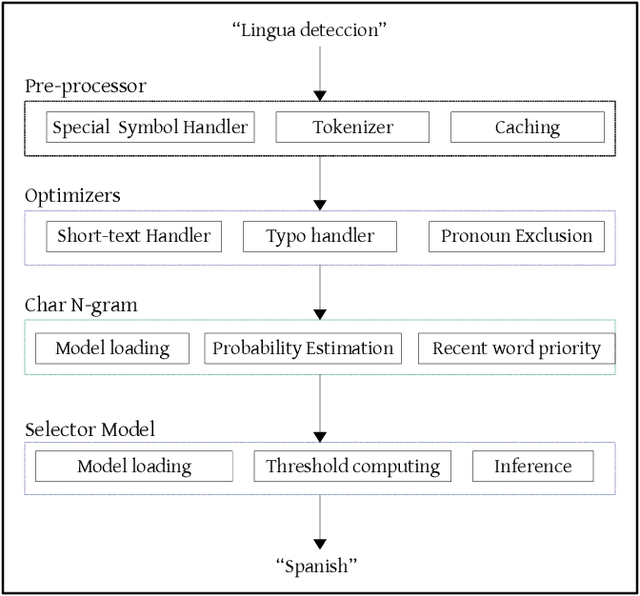

More than 2 billion mobile users worldwide type in multiple languages in the soft keyboard. On a monolingual keyboard, 38% of falsely auto-corrected words are valid in another language. This can be easily avoided by detecting the language of typed words and then validating it in its respective language. Language detection is a well-known problem in natural language processing. In this paper, we present a fast, light-weight and accurate Language Detection Engine (LDE) for multilingual typing that dynamically adapts to user intended language in real-time. We propose a novel approach where the fusion of character N-gram model and logistic regression based selector model is used to identify the language. Additionally, we present a unique method of reducing the inference time significantly by parameter reduction technique. We also discuss various optimizations fabricated across LDE to resolve ambiguity in input text among the languages with the same character pattern. Our method demonstrates an average accuracy of 94.5% for Indian languages in Latin script and that of 98% for European languages on the code-switched data. This model outperforms fastText by 60.39% and ML-Kit by 23.67% in F1 score for European languages. LDE is faster on mobile device with an average inference time of 25.91 microseconds.
* 2020 IEEE 14th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/9031474
Real-Time Optimized N-gram For Mobile Devices
Jan 07, 2021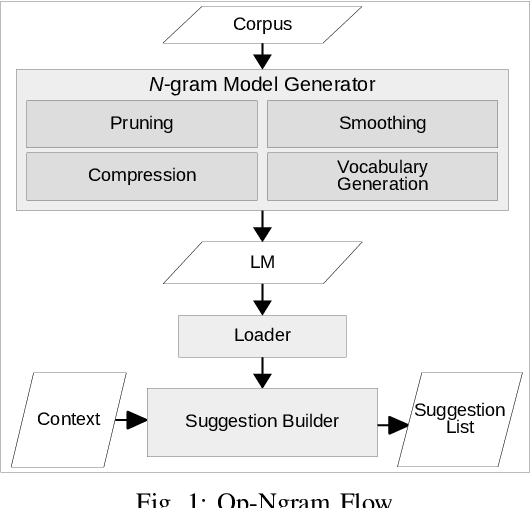
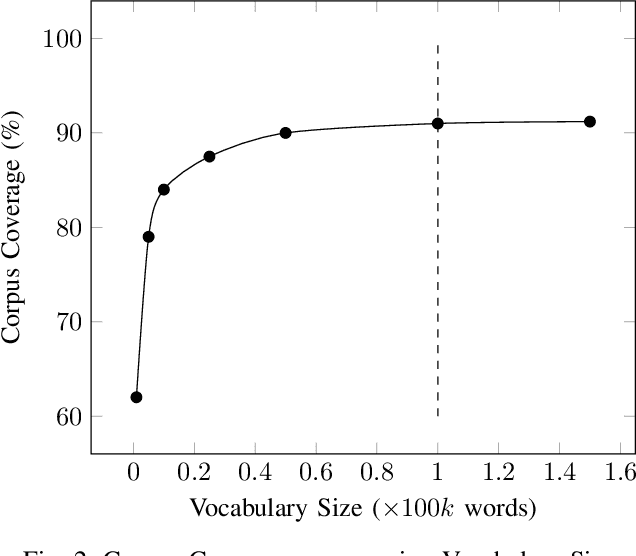
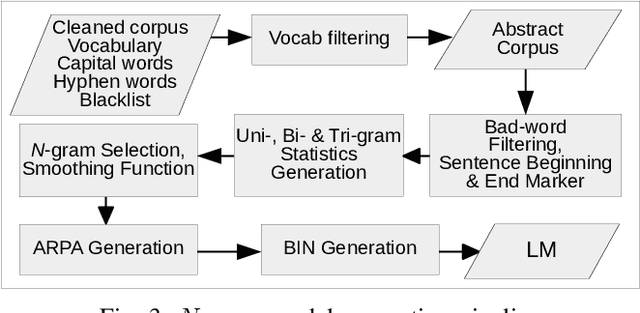

With the increasing number of mobile devices, there has been continuous research on generating optimized Language Models (LMs) for soft keyboard. In spite of advances in this domain, building a single LM for low-end feature phones as well as high-end smartphones is still a pressing need. Hence, we propose a novel technique, Optimized N-gram (Op-Ngram), an end-to-end N-gram pipeline that utilises mobile resources efficiently for faster Word Completion (WC) and Next Word Prediction (NWP). Op-Ngram applies Stupid Backoff and pruning strategies to generate a light-weight model. The LM loading time on mobile is linear with respect to model size. We observed that Op-Ngram gives 37% improvement in Language Model (LM)-ROM size, 76% in LM-RAM size, 88% in loading time and 89% in average suggestion time as compared to SORTED array variant of BerkeleyLM. Moreover, our method shows significant performance improvement over KenLM as well.
* 2019 IEEE 13th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/8665639