 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFONTNET: On-Device Font Understanding and Prediction Pipeline
Mar 30, 2021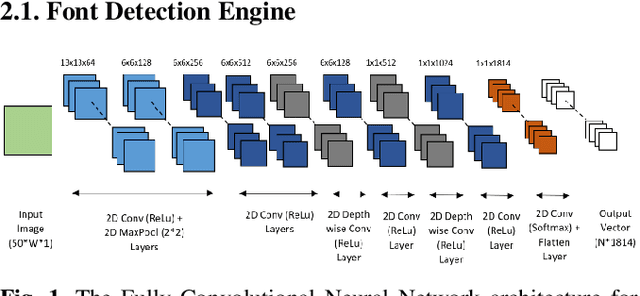
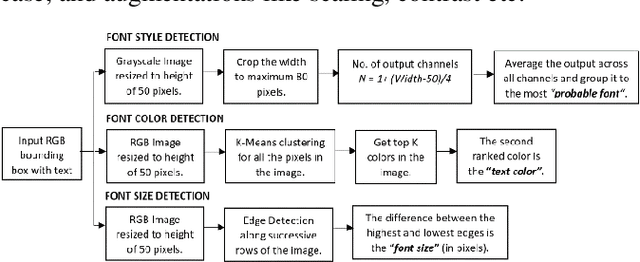
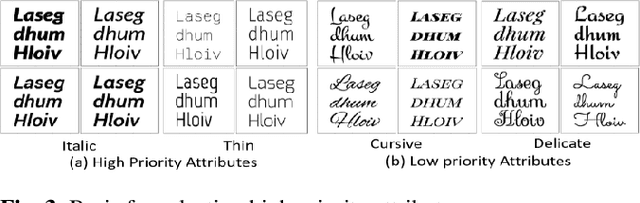
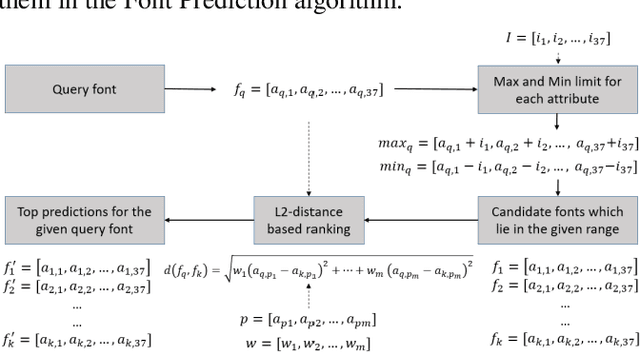
Fonts are one of the most basic and core design concepts. Numerous use cases can benefit from an in depth understanding of Fonts such as Text Customization which can change text in an image while maintaining the Font attributes like style, color, size. Currently, Text recognition solutions can group recognized text based on line breaks or paragraph breaks, if the Font attributes are known multiple text blocks can be combined based on context in a meaningful manner. In this paper, we propose two engines: Font Detection Engine, which identifies the font style, color and size attributes of text in an image and a Font Prediction Engine, which predicts similar fonts for a query font. Major contributions of this paper are three-fold: First, we developed a novel CNN architecture for identifying font style of text in images. Second, we designed a novel algorithm for predicting similar fonts for a given query font. Third, we have optimized and deployed the entire engine On-Device which ensures privacy and improves latency in real time applications such as instant messaging. We achieve a worst case On-Device inference time of 30ms and a model size of 4.5MB for both the engines.
Language Detection Engine for Multilingual Texting on Mobile Devices
Jan 07, 2021

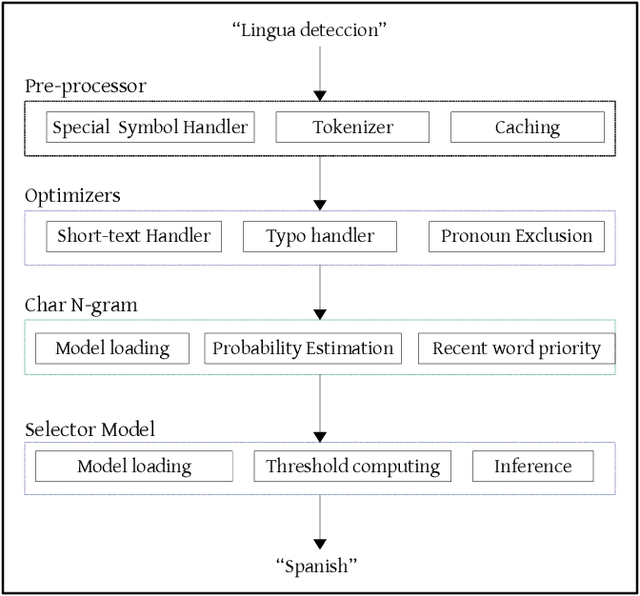

More than 2 billion mobile users worldwide type in multiple languages in the soft keyboard. On a monolingual keyboard, 38% of falsely auto-corrected words are valid in another language. This can be easily avoided by detecting the language of typed words and then validating it in its respective language. Language detection is a well-known problem in natural language processing. In this paper, we present a fast, light-weight and accurate Language Detection Engine (LDE) for multilingual typing that dynamically adapts to user intended language in real-time. We propose a novel approach where the fusion of character N-gram model and logistic regression based selector model is used to identify the language. Additionally, we present a unique method of reducing the inference time significantly by parameter reduction technique. We also discuss various optimizations fabricated across LDE to resolve ambiguity in input text among the languages with the same character pattern. Our method demonstrates an average accuracy of 94.5% for Indian languages in Latin script and that of 98% for European languages on the code-switched data. This model outperforms fastText by 60.39% and ML-Kit by 23.67% in F1 score for European languages. LDE is faster on mobile device with an average inference time of 25.91 microseconds.
* 2020 IEEE 14th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/9031474