 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering
Dec 13, 2023In this work, we propose an efficient Video-Language Alignment via Frame-Prompting and Distilling (VLAP) network. Our VLAP model addresses both efficient frame sampling and effective cross-modal alignment in a unified way. In our VLAP network, we design a new learnable question-aware Frame-Prompter together with a new cross-modal distillation (QFormer-Distiller) module. Pre-trained large image-language models have shown promising results on problems such as visual question answering. However, how to efficiently and effectively sample image frames when adapting pre-trained large image-language model to video-language alignment is still the major challenge. Compared with prior work, our VLAP model demonstrates the capability of selecting key frames with critical contents, thus improving the video-language alignment accuracy while reducing the inference latency (+3.3% on NExT-QA Temporal with 3.0X speed up). Overall, our VLAP network outperforms (e.g. +4.6% on STAR Interaction and +2.2% on STAR average with 3.0X speed up, ours 2-frames out-perform SeViLA 4-frames on VLEP with 4.2X speed up) the state-of-the-art methods on the video question-answering benchmarks.
MeSa: Masked, Geometric, and Supervised Pre-training for Monocular Depth Estimation
Oct 06, 2023Pre-training has been an important ingredient in developing strong monocular depth estimation models in recent years. For instance, self-supervised learning (SSL) is particularly effective by alleviating the need for large datasets with dense ground-truth depth maps. However, despite these improvements, our study reveals that the later layers of the SOTA SSL method are actually suboptimal. By examining the layer-wise representations, we demonstrate significant changes in these later layers during fine-tuning, indicating the ineffectiveness of their pre-trained features for depth estimation. To address these limitations, we propose MeSa, a comprehensive framework that leverages the complementary strengths of masked, geometric, and supervised pre-training. Hence, MeSa benefits from not only general-purpose representations learnt via masked pre training but also specialized depth-specific features acquired via geometric and supervised pre-training. Our CKA layer-wise analysis confirms that our pre-training strategy indeed produces improved representations for the later layers, overcoming the drawbacks of the SOTA SSL method. Furthermore, via experiments on the NYUv2 and IBims-1 datasets, we demonstrate that these enhanced representations translate to performance improvements in both the in-distribution and out-of-distribution settings. We also investigate the influence of the pre-training dataset and demonstrate the efficacy of pre-training on LSUN, which yields significantly better pre-trained representations. Overall, our approach surpasses the masked pre-training SSL method by a substantial margin of 17.1% on the RMSE. Moreover, even without utilizing any recently proposed techniques, MeSa also outperforms the most recent methods and establishes a new state-of-the-art for monocular depth estimation on the challenging NYUv2 dataset.
HR-NeuS: Recovering High-Frequency Surface Geometry via Neural Implicit Surfaces
Feb 14, 2023Recent advances in neural implicit surfaces for multi-view 3D reconstruction primarily focus on improving large-scale surface reconstruction accuracy, but often produce over-smoothed geometries that lack fine surface details. To address this, we present High-Resolution NeuS (HR-NeuS), a novel neural implicit surface reconstruction method that recovers high-frequency surface geometry while maintaining large-scale reconstruction accuracy. We achieve this by utilizing (i) multi-resolution hash grid encoding rather than positional encoding at high frequencies, which boosts our model's expressiveness of local geometry details; (ii) a coarse-to-fine algorithmic framework that selectively applies surface regularization to coarse geometry without smoothing away fine details; (iii) a coarse-to-fine grid annealing strategy to train the network. We demonstrate through experiments on DTU and BlendedMVS datasets that our approach produces 3D geometries that are qualitatively more detailed and quantitatively of similar accuracy compared to previous approaches.
RoomStructNet: Learning to Rank Non-Cuboidal Room Layouts From Single View
Oct 01, 2021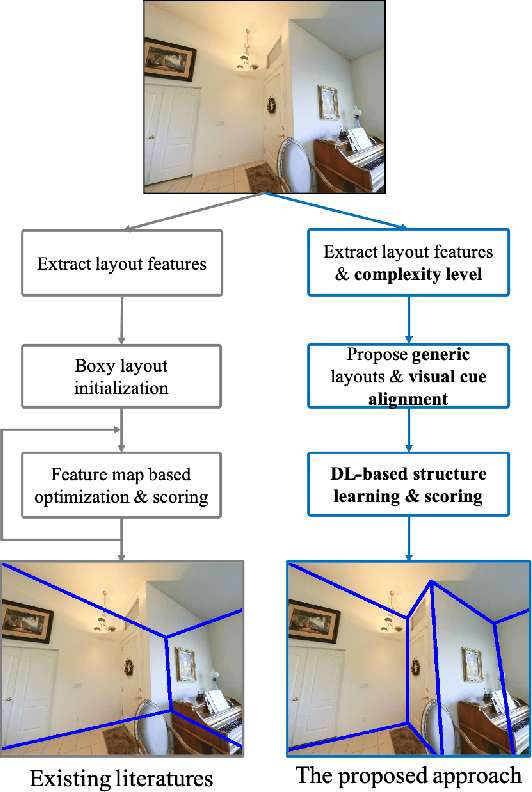
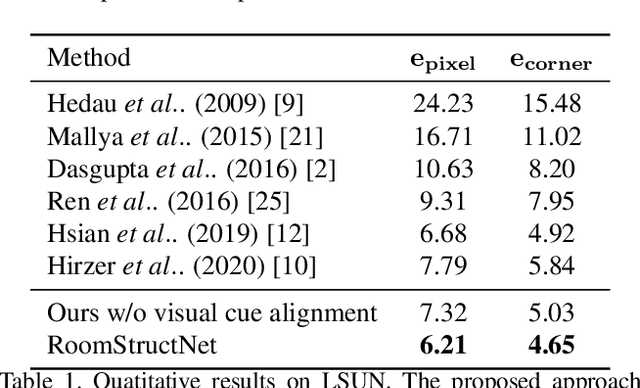
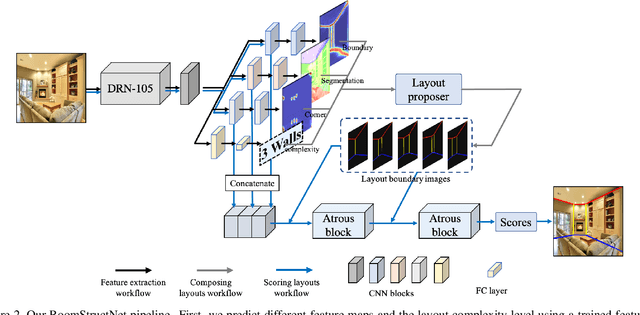
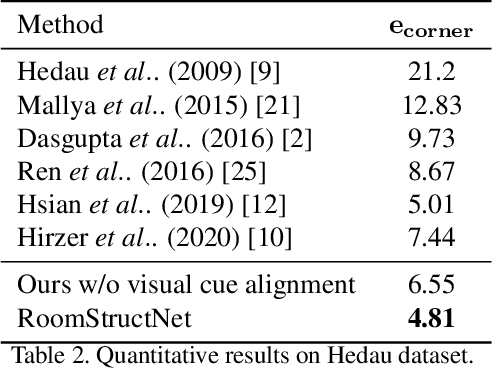
In this paper, we present a new approach to estimate the layout of a room from its single image. While recent approaches for this task use robust features learnt from data, they resort to optimization for detecting the final layout. In addition to using learnt robust features, our approach learns an additional ranking function to estimate the final layout instead of using optimization. To learn this ranking function, we propose a framework to train a CNN using max-margin structure cost. Also, while most approaches aim at detecting cuboidal layouts, our approach detects non-cuboidal layouts for which we explicitly estimates layout complexity parameters. We use these parameters to propose layout candidates in a novel way. Our approach shows state-of-the-art results on standard datasets with mostly cuboidal layouts and also performs well on a dataset containing rooms with non-cuboidal layouts.