 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighting Pseudo-Labels via High-Activation Feature Index Similarity and Object Detection for Semi-Supervised Segmentation
Jul 17, 2024



Semi-supervised semantic segmentation methods leverage unlabeled data by pseudo-labeling them. Thus the success of these methods hinges on the reliablility of the pseudo-labels. Existing methods mostly choose high-confidence pixels in an effort to avoid erroneous pseudo-labels. However, high confidence does not guarantee correct pseudo-labels especially in the initial training iterations. In this paper, we propose a novel approach to reliably learn from pseudo-labels. First, we unify the predictions from a trained object detector and a semantic segmentation model to identify reliable pseudo-label pixels. Second, we assign different learning weights to pseudo-labeled pixels to avoid noisy training signals. To determine these weights, we first use the reliable pseudo-label pixels identified from the first step and labeled pixels to construct a prototype for each class. Then, the per-pixel weight is the structural similarity between the pixel and the prototype measured via rank-statistics similarity. This metric is robust to noise, making it better suited for comparing features from unlabeled images, particularly in the initial training phases where wrong pseudo labels are prone to occur. We show that our method can be easily integrated into four semi-supervised semantic segmentation frameworks, and improves them in both Cityscapes and Pascal VOC datasets.
Beyond Pixels: Semi-Supervised Semantic Segmentation with a Multi-scale Patch-based Multi-Label Classifier
Jul 04, 2024Incorporating pixel contextual information is critical for accurate segmentation. In this paper, we show that an effective way to incorporate contextual information is through a patch-based classifier. This patch classifier is trained to identify classes present within an image region, which facilitates the elimination of distractors and enhances the classification of small object segments. Specifically, we introduce Multi-scale Patch-based Multi-label Classifier (MPMC), a novel plug-in module designed for existing semi-supervised segmentation (SSS) frameworks. MPMC offers patch-level supervision, enabling the discrimination of pixel regions of different classes within a patch. Furthermore, MPMC learns an adaptive pseudo-label weight, using patch-level classification to alleviate the impact of the teacher's noisy pseudo-label supervision the student. This lightweight module can be integrated into any SSS framework, significantly enhancing their performance. We demonstrate the efficacy of our proposed MPMC by integrating it into four SSS methodologies and improving them across two natural image and one medical segmentation dataset, notably improving the segmentation results of the baselines across all the three datasets.
Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks
May 08, 2018
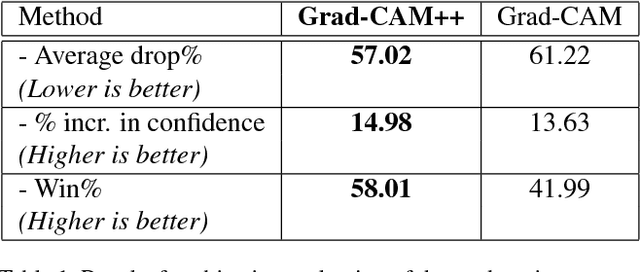
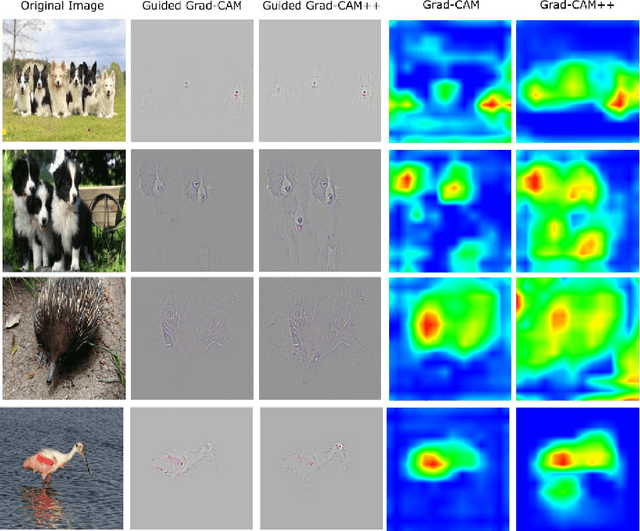
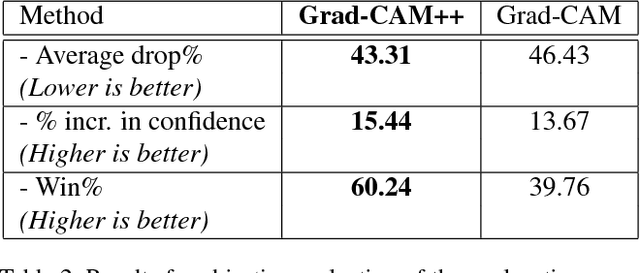
Over the last decade, Convolutional Neural Network (CNN) models have been highly successful in solving complex vision based problems. However, these deep models are perceived as "black box" methods considering the lack of understanding of their internal functioning. There has been a significant recent interest to develop explainable deep learning models, and this paper is an effort in this direction. Building on a recently proposed method called Grad-CAM, we propose a generalized method called Grad-CAM++ that can provide better visual explanations of CNN model predictions, in terms of better object localization as well as explaining occurrences of multiple object instances in a single image, when compared to state-of-the-art. We provide a mathematical derivation for the proposed method, which uses a weighted combination of the positive partial derivatives of the last convolutional layer feature maps with respect to a specific class score as weights to generate a visual explanation for the corresponding class label. Our extensive experiments and evaluations, both subjective and objective, on standard datasets showed that Grad-CAM++ provides promising human-interpretable visual explanations for a given CNN architecture across multiple tasks including classification, image caption generation and 3D action recognition; as well as in new settings such as knowledge distillation.