 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Arithmetic Through The Lens Of One-Shot Federated Learning
Nov 27, 2024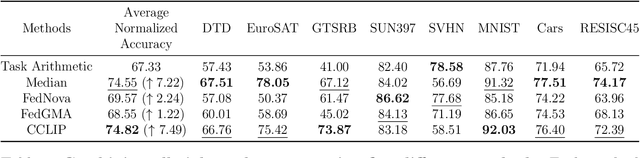
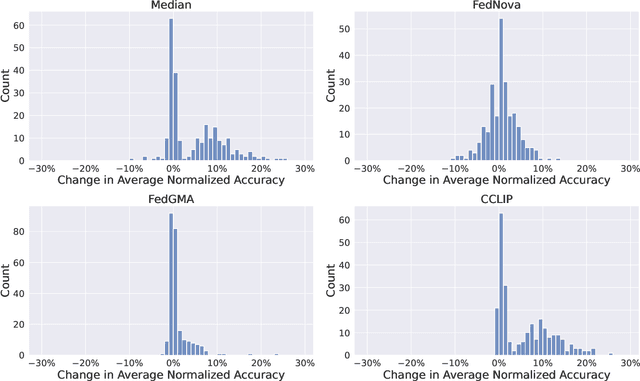
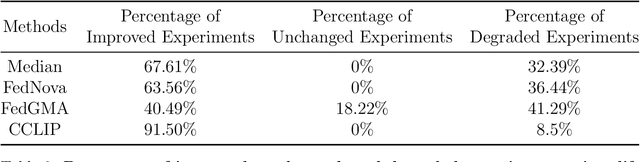
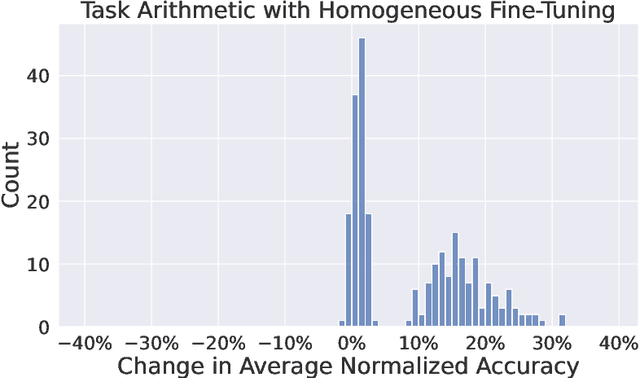
Task Arithmetic is a model merging technique that enables the combination of multiple models' capabilities into a single model through simple arithmetic in the weight space, without the need for additional fine-tuning or access to the original training data. However, the factors that determine the success of Task Arithmetic remain unclear. In this paper, we examine Task Arithmetic for multi-task learning by framing it as a one-shot Federated Learning problem. We demonstrate that Task Arithmetic is mathematically equivalent to the commonly used algorithm in Federated Learning, called Federated Averaging (FedAvg). By leveraging well-established theoretical results from FedAvg, we identify two key factors that impact the performance of Task Arithmetic: data heterogeneity and training heterogeneity. To mitigate these challenges, we adapt several algorithms from Federated Learning to improve the effectiveness of Task Arithmetic. Our experiments demonstrate that applying these algorithms can often significantly boost performance of the merged model compared to the original Task Arithmetic approach. This work bridges Task Arithmetic and Federated Learning, offering new theoretical perspectives on Task Arithmetic and improved practical methodologies for model merging.
Modularity Trumps Invariance for Compositional Robustness
Jun 15, 2023
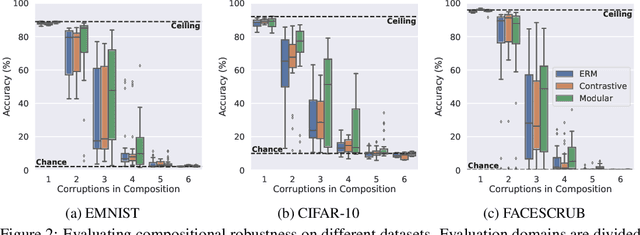
By default neural networks are not robust to changes in data distribution. This has been demonstrated with simple image corruptions, such as blurring or adding noise, degrading image classification performance. Many methods have been proposed to mitigate these issues but for the most part models are evaluated on single corruptions. In reality, visual space is compositional in nature, that is, that as well as robustness to elemental corruptions, robustness to compositions of corruptions is also needed. In this work we develop a compositional image classification task where, given a few elemental corruptions, models are asked to generalize to compositions of these corruptions. That is, to achieve compositional robustness. We experimentally compare empirical risk minimization with an invariance building pairwise contrastive loss and, counter to common intuitions in domain generalization, achieve only marginal improvements in compositional robustness by encouraging invariance. To move beyond invariance, following previously proposed inductive biases that model architectures should reflect data structure, we introduce a modular architecture whose structure replicates the compositional nature of the task. We then show that this modular approach consistently achieves better compositional robustness than non-modular approaches. We additionally find empirical evidence that the degree of invariance between representations of 'in-distribution' elemental corruptions fails to correlate with robustness to 'out-of-distribution' compositions of corruptions.
Deephys: Deep Electrophysiology, Debugging Neural Networks under Distribution Shifts
Mar 17, 2023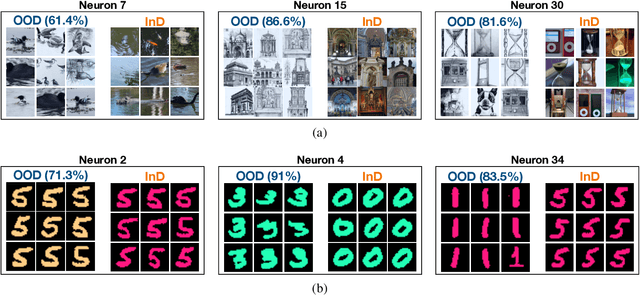
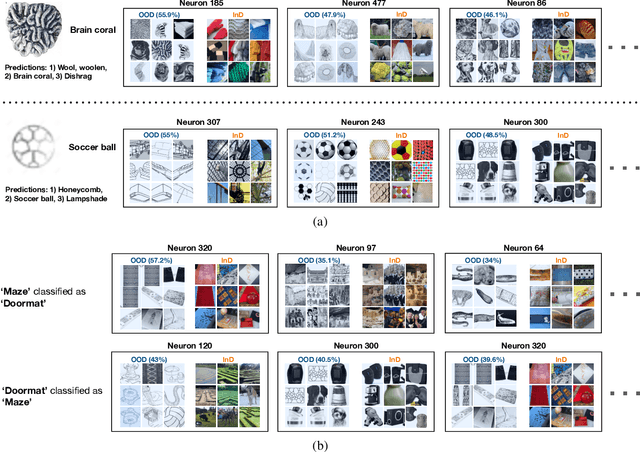
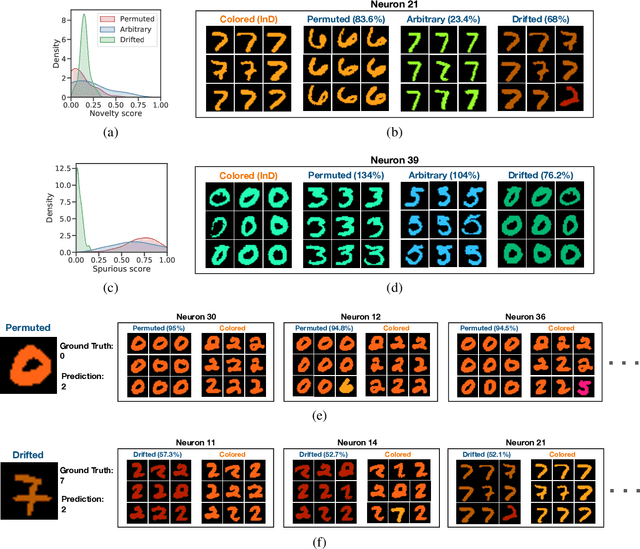
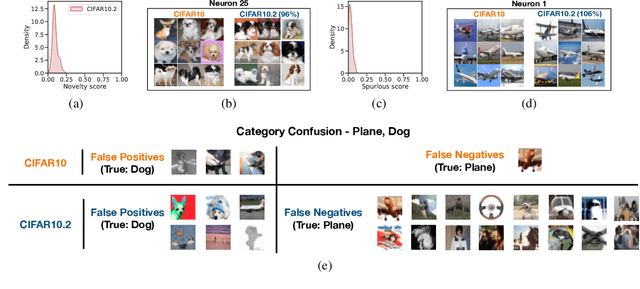
Deep Neural Networks (DNNs) often fail in out-of-distribution scenarios. In this paper, we introduce a tool to visualize and understand such failures. We draw inspiration from concepts from neural electrophysiology, which are based on inspecting the internal functioning of a neural networks by analyzing the feature tuning and invariances of individual units. Deep Electrophysiology, in short Deephys, provides insights of the DNN's failures in out-of-distribution scenarios by comparative visualization of the neural activity in in-distribution and out-of-distribution datasets. Deephys provides seamless analyses of individual neurons, individual images, and a set of set of images from a category, and it is capable of revealing failures due to the presence of spurious features and novel features. We substantiate the validity of the qualitative visualizations of Deephys thorough quantitative analyses using convolutional and transformers architectures, in several datasets and distribution shifts (namely, colored MNIST, CIFAR-10 and ImageNet).
Real-Time Style Modelling of Human Locomotion via Feature-Wise Transformations and Local Motion Phases
Jan 12, 2022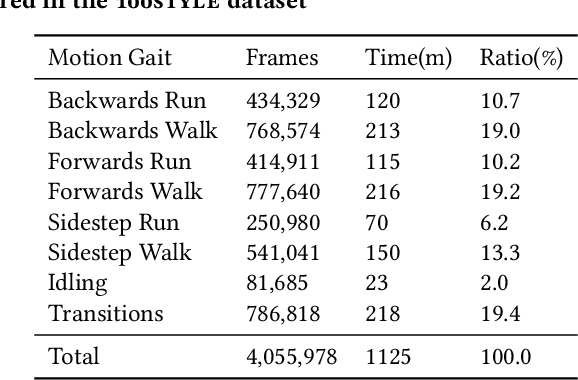


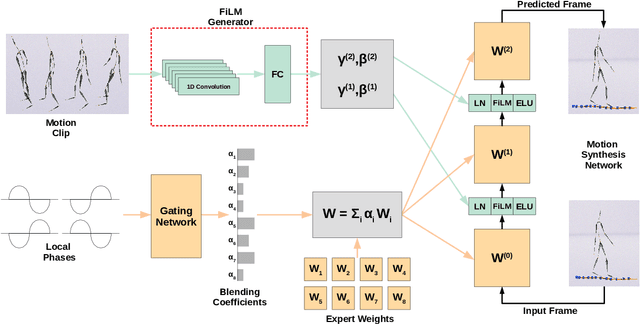
Controlling the manner in which a character moves in a real-time animation system is a challenging task with useful applications. Existing style transfer systems require access to a reference content motion clip, however, in real-time systems the future motion content is unknown and liable to change with user input. In this work we present a style modelling system that uses an animation synthesis network to model motion content based on local motion phases. An additional style modulation network uses feature-wise transformations to modulate style in real-time. To evaluate our method, we create and release a new style modelling dataset, 100STYLE, containing over 4 million frames of stylised locomotion data in 100 different styles that present a number of challenges for existing systems. To model these styles, we extend the local phase calculation with a contact-free formulation. In comparison to other methods for real-time style modelling, we show our system is more robust and efficient in its style representation while improving motion quality.
Source-Free Adaptation to Measurement Shift via Bottom-Up Feature Restoration
Jul 12, 2021
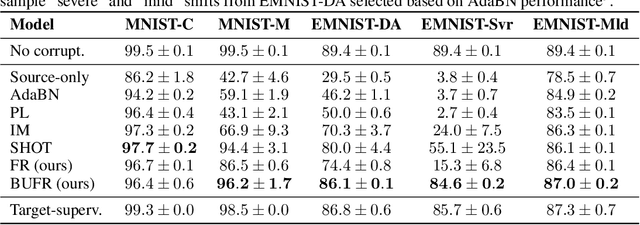
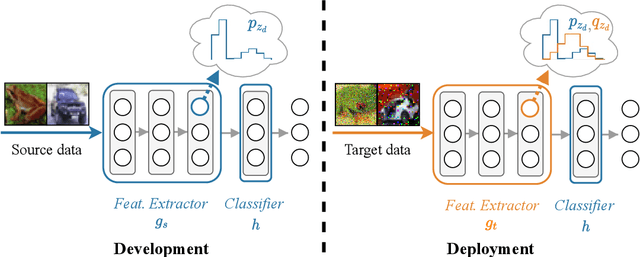
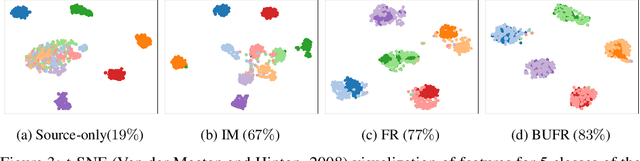
Source-free domain adaptation (SFDA) aims to adapt a model trained on labelled data in a source domain to unlabelled data in a target domain without access to the source-domain data during adaptation. Existing methods for SFDA leverage entropy-minimization techniques which: (i) apply only to classification; (ii) destroy model calibration; and (iii) rely on the source model achieving a good level of feature-space class-separation in the target domain. We address these issues for a particularly pervasive type of domain shift called measurement shift, characterized by a change in measurement system (e.g. a change in sensor or lighting). In the source domain, we store a lightweight and flexible approximation of the feature distribution under the source data. In the target domain, we adapt the feature-extractor such that the approximate feature distribution under the target data realigns with that saved on the source. We call this method Feature Restoration (FR) as it seeks to extract features with the same semantics from the target domain as were previously extracted from the source. We additionally propose Bottom-Up Feature Restoration (BUFR), a bottom-up training scheme for FR which boosts performance by preserving learnt structure in the later layers of a network. Through experiments we demonstrate that BUFR often outperforms existing SFDA methods in terms of accuracy, calibration, and data efficiency, while being less reliant on the performance of the source model in the target domain.