 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimension Free Generalization Bounds for Non Linear Metric Learning
Paper and Code
Feb 07, 2021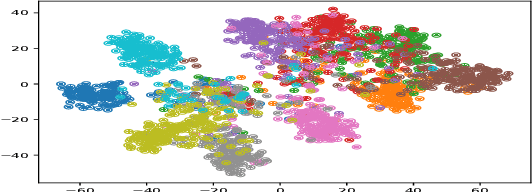
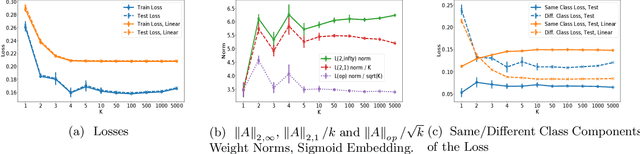
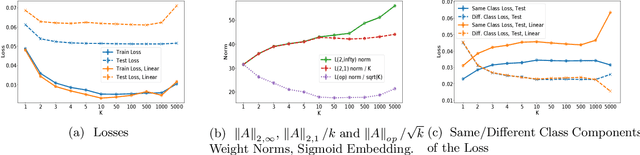
In this work we study generalization guarantees for the metric learning problem, where the metric is induced by a neural network type embedding of the data. Specifically, we provide uniform generalization bounds for two regimes -- the sparse regime, and a non-sparse regime which we term \emph{bounded amplification}. The sparse regime bounds correspond to situations where $\ell_1$-type norms of the parameters are small. Similarly to the situation in classification, solutions satisfying such bounds can be obtained by an appropriate regularization of the problem. On the other hand, unregularized SGD optimization of a metric learning loss typically does not produce sparse solutions. We show that despite this lack of sparsity, by relying on a different, new property of the solutions, it is still possible to provide dimension free generalization guarantees. Consequently, these bounds can explain generalization in non sparse real experimental situations. We illustrate the studied phenomena on the MNIST and 20newsgroups datasets.