 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Word Segmentation and Morpheme Segmentation as Sequence Labelling
Paper and Code
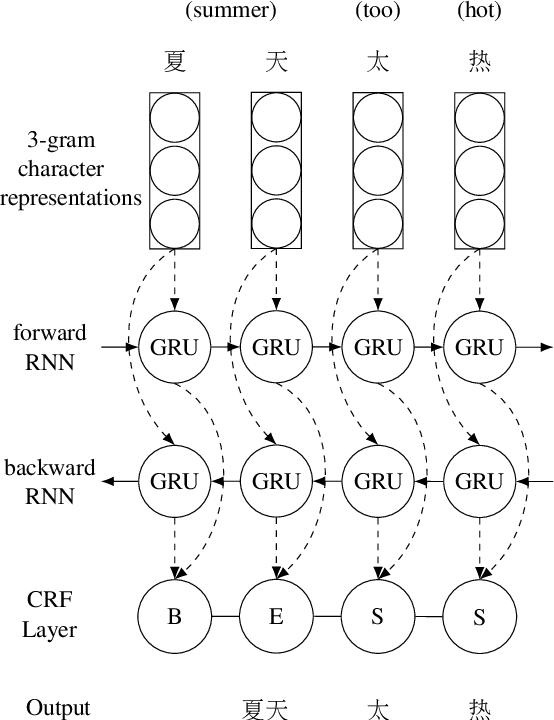


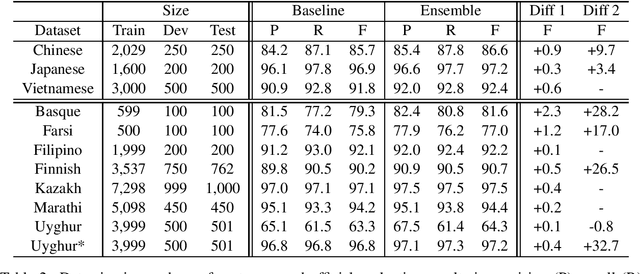
This paper presents our segmentation system developed for the MLP 2017 shared tasks on cross-lingual word segmentation and morpheme segmentation. We model both word and morpheme segmentation as character-level sequence labelling tasks. The prevalent bidirectional recurrent neural network with conditional random fields as the output interface is adapted as the baseline system, which is further improved via ensemble decoding. Our universal system is applied to and extensively evaluated on all the official data sets without any language-specific adjustment. The official evaluation results indicate that the proposed model achieves outstanding accuracies both for word and morpheme segmentation on all the languages in various types when compared to the other participating systems.