 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-MedSAM: Uncertainty-aware MedSAM for Medical Image Segmentation
Aug 03, 2024



Medical Image Foundation Models have proven to be powerful tools for mask prediction across various datasets. However, accurately assessing the uncertainty of their predictions remains a significant challenge. To address this, we propose a new model, U-MedSAM, which integrates the MedSAM model with an uncertainty-aware loss function and the Sharpness-Aware Minimization (SharpMin) optimizer. The uncertainty-aware loss function automatically combines region-based, distribution-based, and pixel-based loss designs to enhance segmentation accuracy and robustness. SharpMin improves generalization by finding flat minima in the loss landscape, thereby reducing overfitting. Our method was evaluated in the CVPR24 MedSAM on Laptop challenge, where U-MedSAM demonstrated promising performance.
RelationRS: Relationship Representation Network for Object Detection in Aerial Images
Oct 13, 2021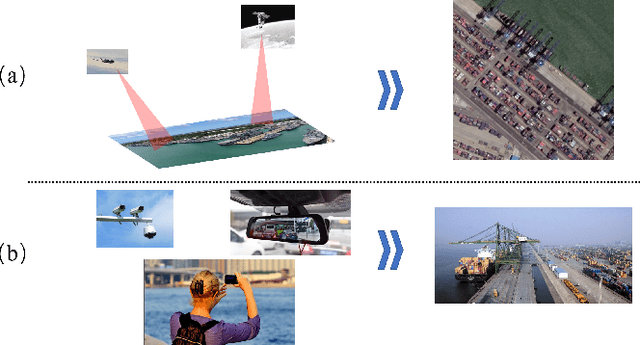
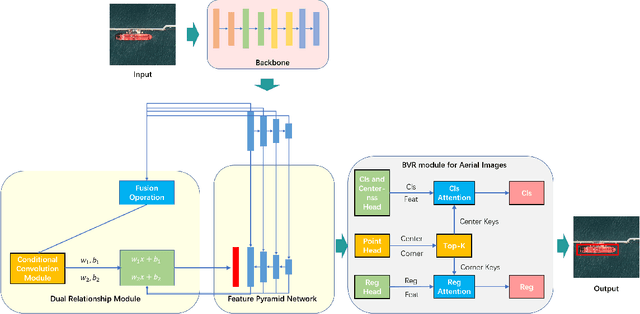


Object detection is a basic and important task in the field of aerial image processing and has gained much attention in computer vision. However, previous aerial image object detection approaches have insufficient use of scene semantic information between different regions of large-scale aerial images. In addition, complex background and scale changes make it difficult to improve detection accuracy. To address these issues, we propose a relationship representation network for object detection in aerial images (RelationRS): 1) Firstly, multi-scale features are fused and enhanced by a dual relationship module (DRM) with conditional convolution. The dual relationship module learns the potential relationship between features of different scales and learns the relationship between different scenes from different patches in a same iteration. In addition, the dual relationship module dynamically generates parameters to guide the fusion of multi-scale features. 2) Secondly, The bridging visual representations module (BVR) is introduced into the field of aerial images to improve the object detection effect in images with complex backgrounds. Experiments with a publicly available object detection dataset for aerial images demonstrate that the proposed RelationRS achieves a state-of-the-art detection performance.
Deep Representation Learning for Road Detection through Siamese Network
May 26, 2019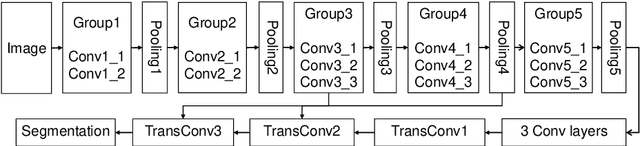
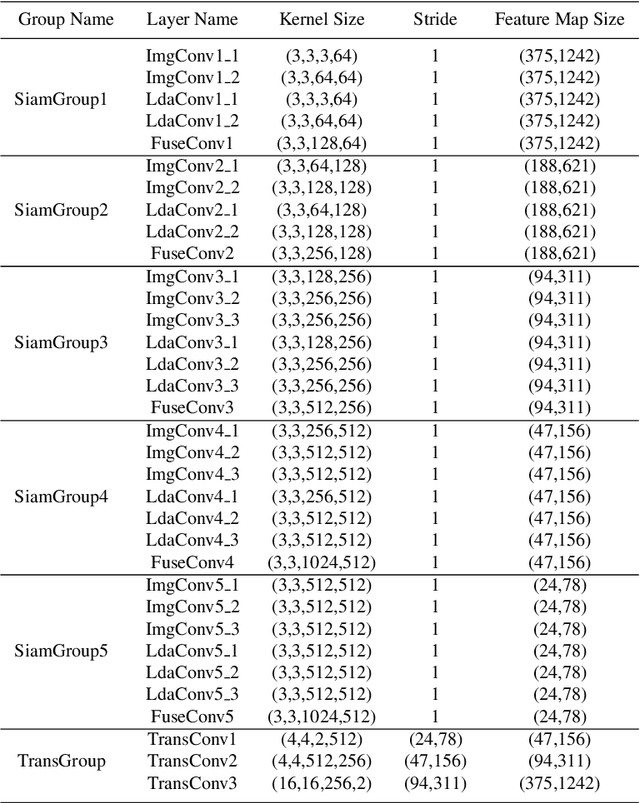

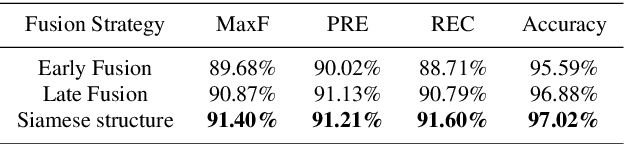
Robust road detection is a key challenge in safe autonomous driving. Recently, with the rapid development of 3D sensors, more and more researchers are trying to fuse information across different sensors to improve the performance of road detection. Although many successful works have been achieved in this field, methods for data fusion under deep learning framework is still an open problem. In this paper, we propose a Siamese deep neural network based on FCN-8s to detect road region. Our method uses data collected from a monocular color camera and a Velodyne-64 LiDAR sensor. We project the LiDAR point clouds onto the image plane to generate LiDAR images and feed them into one of the branches of the network. The RGB images are fed into another branch of our proposed network. The feature maps that these two branches extract in multiple scales are fused before each pooling layer, via padding additional fusion layers. Extensive experimental results on public dataset KITTI ROAD demonstrate the effectiveness of our proposed approach.