 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf and Cross-Model Distillation for LLMs: Effective Methods for Refusal Pattern Alignment
Jun 17, 2024Large Language Models (LLMs) like OpenAI's GPT series, Anthropic's Claude, and Meta's LLaMa have shown remarkable capabilities in text generation. However, their susceptibility to toxic prompts presents significant security challenges. This paper investigates alignment techniques, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), to mitigate these risks. We conduct an empirical study on refusal patterns across nine LLMs, revealing that models with uniform refusal patterns, such as Claude3, exhibit higher security. Based on these findings, we propose self-distilling and cross-model distilling methods to enhance LLM security. Our results show that these methods significantly improve refusal rates and reduce unsafe content, with cross-model distilling achieving refusal rates close to Claude3's 94.51%. These findings underscore the potential of distillation-based alignment in securing LLMs against toxic prompts.
A Cross-Language Investigation into Jailbreak Attacks in Large Language Models
Jan 30, 2024Large Language Models (LLMs) have become increasingly popular for their advanced text generation capabilities across various domains. However, like any software, they face security challenges, including the risk of 'jailbreak' attacks that manipulate LLMs to produce prohibited content. A particularly underexplored area is the Multilingual Jailbreak attack, where malicious questions are translated into various languages to evade safety filters. Currently, there is a lack of comprehensive empirical studies addressing this specific threat. To address this research gap, we conducted an extensive empirical study on Multilingual Jailbreak attacks. We developed a novel semantic-preserving algorithm to create a multilingual jailbreak dataset and conducted an exhaustive evaluation on both widely-used open-source and commercial LLMs, including GPT-4 and LLaMa. Additionally, we performed interpretability analysis to uncover patterns in Multilingual Jailbreak attacks and implemented a fine-tuning mitigation method. Our findings reveal that our mitigation strategy significantly enhances model defense, reducing the attack success rate by 96.2%. This study provides valuable insights into understanding and mitigating Multilingual Jailbreak attacks.
RelationRS: Relationship Representation Network for Object Detection in Aerial Images
Oct 13, 2021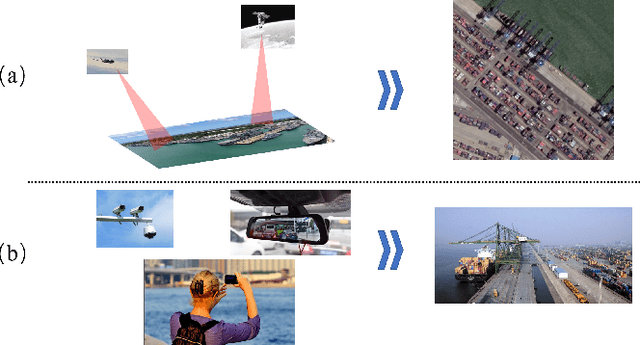
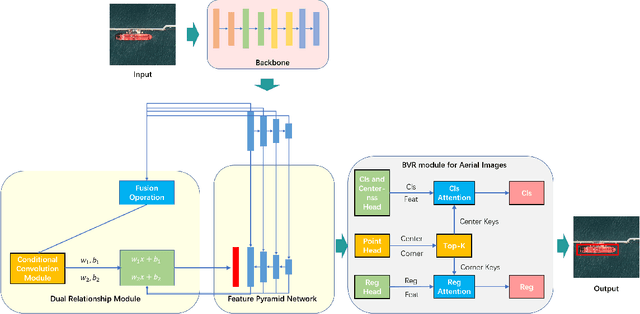


Object detection is a basic and important task in the field of aerial image processing and has gained much attention in computer vision. However, previous aerial image object detection approaches have insufficient use of scene semantic information between different regions of large-scale aerial images. In addition, complex background and scale changes make it difficult to improve detection accuracy. To address these issues, we propose a relationship representation network for object detection in aerial images (RelationRS): 1) Firstly, multi-scale features are fused and enhanced by a dual relationship module (DRM) with conditional convolution. The dual relationship module learns the potential relationship between features of different scales and learns the relationship between different scenes from different patches in a same iteration. In addition, the dual relationship module dynamically generates parameters to guide the fusion of multi-scale features. 2) Secondly, The bridging visual representations module (BVR) is introduced into the field of aerial images to improve the object detection effect in images with complex backgrounds. Experiments with a publicly available object detection dataset for aerial images demonstrate that the proposed RelationRS achieves a state-of-the-art detection performance.