 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Anisotropic Cross-Lingual Model Editing
Paper and Code
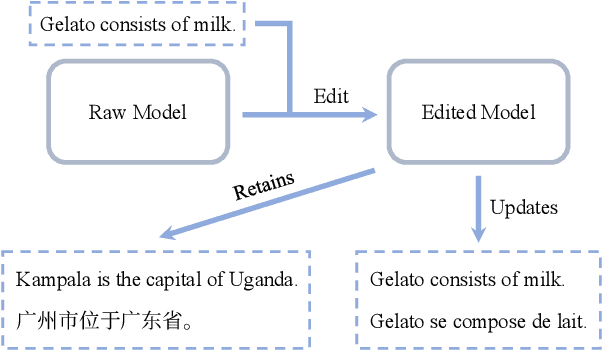

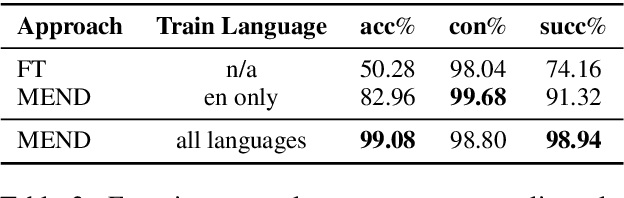

Pre-trained language models learn large amounts of knowledge from their training corpus, while the memorized facts could become outdated over a few years. Model editing aims to make post-hoc updates on specific facts in a model while leaving irrelevant knowledge unchanged. However, existing work studies only the monolingual scenario. In this paper, we focus on cross-lingual model editing. Firstly, we propose the definition and metrics of the cross-lingual model editing, where updates in a single language should take effect in the others as well. Next, we propose a simple framework to convert a monolingual model editing approach to its cross-lingual variant using the parallel corpus. Experiments show that such an approach outperforms monolingual baselines by a large margin. Furthermore, we propose language anisotropic editing to improve cross-lingual editing by estimating parameter importance for each language. Experiments reveal that language anisotropic editing decreases the editing failing rate by another $26\%$ relatively.