 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKCLNet: Electrically Equivalence-Oriented Graph Representation Learning for Analog Circuits
Mar 25, 2026Digital circuits representation learning has made remarkable progress in the electronic design automation domain, effectively supporting critical tasks such as testability analysis and logic reasoning. However, representation learning for analog circuits remains challenging due to their continuous electrical characteristics compared to the discrete states of digital circuits. This paper presents a direct current (DC) electrically equivalent-oriented analog representation learning framework, named \textbf{KCLNet}. It comprises an asynchronous graph neural network structure with electrically-simulated message passing and a representation learning method inspired by Kirchhoff's Current Law (KCL). This method maintains the orderliness of the circuit embedding space by enforcing the equality of the sum of outgoing and incoming current embeddings at each depth, which significantly enhances the generalization ability of circuit embeddings. KCLNet offers a novel and effective solution for analog circuit representation learning with electrical constraints preserved. Experimental results demonstrate that our method achieves significant performance in a variety of downstream tasks, e.g., analog circuit classification, subcircuit detection, and circuit edit distance prediction.
LMM-IR: Large-Scale Netlist-Aware Multimodal Framework for Static IR-Drop Prediction
Nov 16, 2025Static IR drop analysis is a fundamental and critical task in the field of chip design. Nevertheless, this process can be quite time-consuming, potentially requiring several hours. Moreover, addressing IR drop violations frequently demands iterative analysis, thereby causing the computational burden. Therefore, fast and accurate IR drop prediction is vital for reducing the overall time invested in chip design. In this paper, we firstly propose a novel multimodal approach that efficiently processes SPICE files through large-scale netlist transformer (LNT). Our key innovation is representing and processing netlist topology as 3D point cloud representations, enabling efficient handling of netlist with up to hundreds of thousands to millions nodes. All types of data, including netlist files and image data, are encoded into latent space as features and fed into the model for static voltage drop prediction. This enables the integration of data from multiple modalities for complementary predictions. Experimental results demonstrate that our proposed algorithm can achieve the best F1 score and the lowest MAE among the winning teams of the ICCAD 2023 contest and the state-of-the-art algorithms.
Learning-driven Physically-aware Large-scale Circuit Gate Sizing
Mar 13, 2024



Gate sizing plays an important role in timing optimization after physical design. Existing machine learning-based gate sizing works cannot optimize timing on multiple timing paths simultaneously and neglect the physical constraint on layouts. They cause sub-optimal sizing solutions and low-efficiency issues when compared with commercial gate sizing tools. In this work, we propose a learning-driven physically-aware gate sizing framework to optimize timing performance on large-scale circuits efficiently. In our gradient descent optimization-based work, for obtaining accurate gradients, a multi-modal gate sizing-aware timing model is achieved via learning timing information on multiple timing paths and physical information on multiple-scaled layouts jointly. Then, gradient generation based on the sizing-oriented estimator and adaptive back-propagation are developed to update gate sizes. Our results demonstrate that our work achieves higher timing performance improvements in a faster way compared with the commercial gate sizing tool.
Recent Advances in Convolutional Neural Network Acceleration
Jul 23, 2018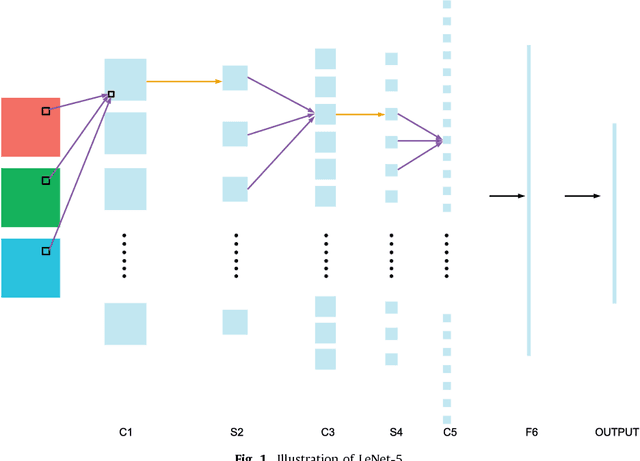



In recent years, convolutional neural networks (CNNs) have shown great performance in various fields such as image classification, pattern recognition, and multi-media compression. Two of the feature properties, local connectivity and weight sharing, can reduce the number of parameters and increase processing speed during training and inference. However, as the dimension of data becomes higher and the CNN architecture becomes more complicated, the end-to-end approach or the combined manner of CNN is computationally intensive, which becomes limitation to CNN's further implementation. Therefore, it is necessary and urgent to implement CNN in a faster way. In this paper, we first summarize the acceleration methods that contribute to but not limited to CNN by reviewing a broad variety of research papers. We propose a taxonomy in terms of three levels, i.e.~structure level, algorithm level, and implementation level, for acceleration methods. We also analyze the acceleration methods in terms of CNN architecture compression, algorithm optimization, and hardware-based improvement. At last, we give a discussion on different perspectives of these acceleration and optimization methods within each level. The discussion shows that the methods in each level still have large exploration space. By incorporating such a wide range of disciplines, we expect to provide a comprehensive reference for researchers who are interested in CNN acceleration.