 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Convolutional Neural Network Acceleration
Jul 23, 2018



In recent years, convolutional neural networks (CNNs) have shown great performance in various fields such as image classification, pattern recognition, and multi-media compression. Two of the feature properties, local connectivity and weight sharing, can reduce the number of parameters and increase processing speed during training and inference. However, as the dimension of data becomes higher and the CNN architecture becomes more complicated, the end-to-end approach or the combined manner of CNN is computationally intensive, which becomes limitation to CNN's further implementation. Therefore, it is necessary and urgent to implement CNN in a faster way. In this paper, we first summarize the acceleration methods that contribute to but not limited to CNN by reviewing a broad variety of research papers. We propose a taxonomy in terms of three levels, i.e.~structure level, algorithm level, and implementation level, for acceleration methods. We also analyze the acceleration methods in terms of CNN architecture compression, algorithm optimization, and hardware-based improvement. At last, we give a discussion on different perspectives of these acceleration and optimization methods within each level. The discussion shows that the methods in each level still have large exploration space. By incorporating such a wide range of disciplines, we expect to provide a comprehensive reference for researchers who are interested in CNN acceleration.
Transfer Learning via Latent Factor Modeling to Improve Prediction of Surgical Complications
Dec 02, 2016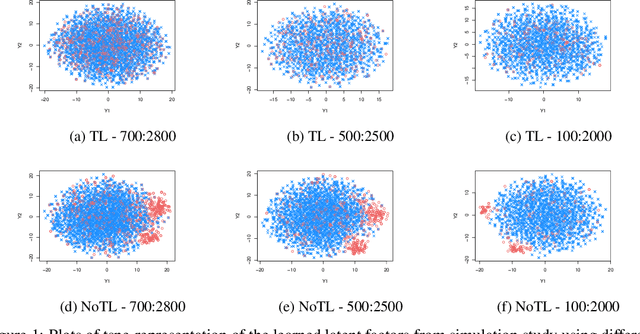

We aim to create a framework for transfer learning using latent factor models to learn the dependence structure between a larger source dataset and a target dataset. The methodology is motivated by our goal of building a risk-assessment model for surgery patients, using both institutional and national surgical outcomes data. The national surgical outcomes data is collected through NSQIP (National Surgery Quality Improvement Program), a database housing almost 4 million patients from over 700 different hospitals. We build a latent factor model with a hierarchical prior on the loadings matrix to appropriately account for the different covariance structure in our data. We extend this model to handle more complex relationships between the populations by deriving a scale mixture formulation using stick-breaking properties. Our model provides a transfer learning framework that utilizes all information from both the source and target data, while modeling the underlying inherent differences between them.