 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidance Design for Escape Flight Vehicle Using Evolution Strategy Enhanced Deep Reinforcement Learning
May 04, 2024Guidance commands of flight vehicles are a series of data sets with fixed time intervals, thus guidance design constitutes a sequential decision problem and satisfies the basic conditions for using deep reinforcement learning (DRL). In this paper, we consider the scenario where the escape flight vehicle (EFV) generates guidance commands based on DRL and the pursuit flight vehicle (PFV) generates guidance commands based on the proportional navigation method. For the EFV, the objective of the guidance design entails progressively maximizing the residual velocity, subject to the constraint imposed by the given evasion distance. Thus an irregular dynamic max-min problem of extremely large-scale is formulated, where the time instant when the optimal solution can be attained is uncertain and the optimum solution depends on all the intermediate guidance commands generated before. For solving this problem, a two-step strategy is conceived. In the first step, we use the proximal policy optimization (PPO) algorithm to generate the guidance commands of the EFV. The results obtained by PPO in the global search space are coarse, despite the fact that the reward function, the neural network parameters and the learning rate are designed elaborately. Therefore, in the second step, we propose to invoke the evolution strategy (ES) based algorithm, which uses the result of PPO as the initial value, to further improve the quality of the solution by searching in the local space. Simulation results demonstrate that the proposed guidance design method based on the PPO algorithm is capable of achieving a residual velocity of 67.24 m/s, higher than the residual velocities achieved by the benchmark soft actor-critic and deep deterministic policy gradient algorithms. Furthermore, the proposed ES-enhanced PPO algorithm outperforms the PPO algorithm by 2.7\%, achieving a residual velocity of 69.04 m/s.
* 13 pages, 13 figures, accepted to appear on IEEE Access, Mar. 2024
From Good to Best: Two-Stage Training for Cross-lingual Machine Reading Comprehension
Dec 09, 2021
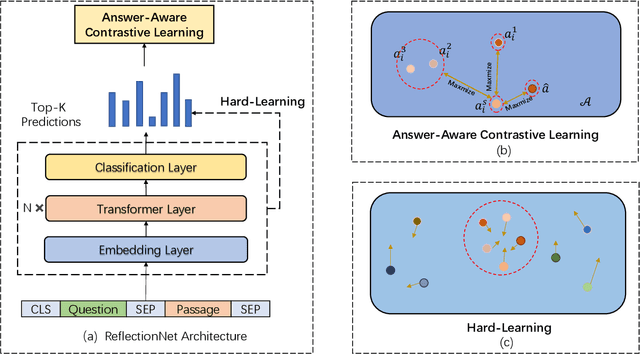
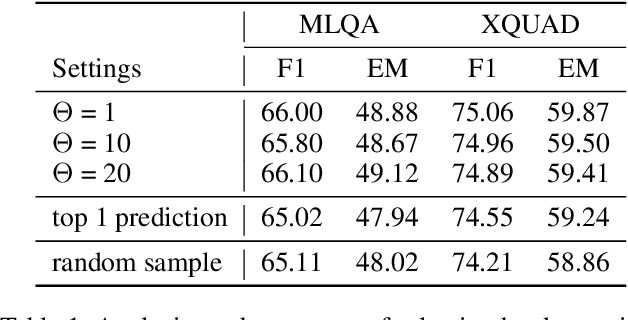
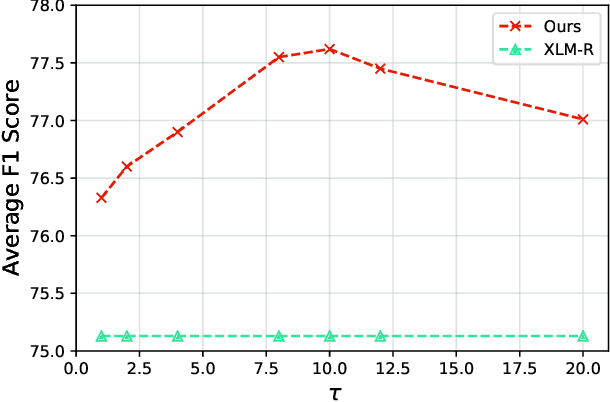
Cross-lingual Machine Reading Comprehension (xMRC) is challenging due to the lack of training data in low-resource languages. The recent approaches use training data only in a resource-rich language like English to fine-tune large-scale cross-lingual pre-trained language models. Due to the big difference between languages, a model fine-tuned only by a source language may not perform well for target languages. Interestingly, we observe that while the top-1 results predicted by the previous approaches may often fail to hit the ground-truth answers, the correct answers are often contained in the top-k predicted results. Based on this observation, we develop a two-stage approach to enhance the model performance. The first stage targets at recall: we design a hard-learning (HL) algorithm to maximize the likelihood that the top-k predictions contain the accurate answer. The second stage focuses on precision: an answer-aware contrastive learning (AA-CL) mechanism is developed to learn the fine difference between the accurate answer and other candidates. Our extensive experiments show that our model significantly outperforms a series of strong baselines on two cross-lingual MRC benchmark datasets.