 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Good to Best: Two-Stage Training for Cross-lingual Machine Reading Comprehension
Paper and Code

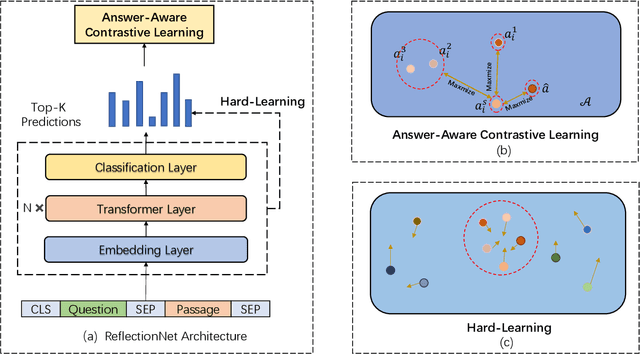
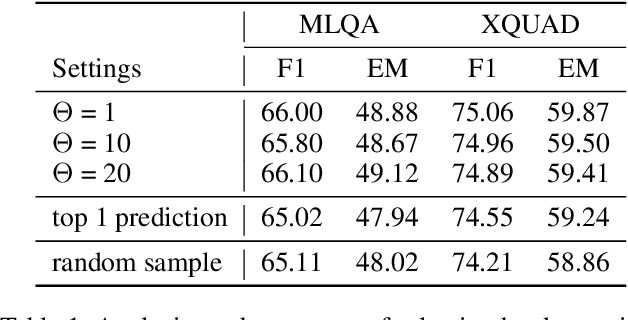
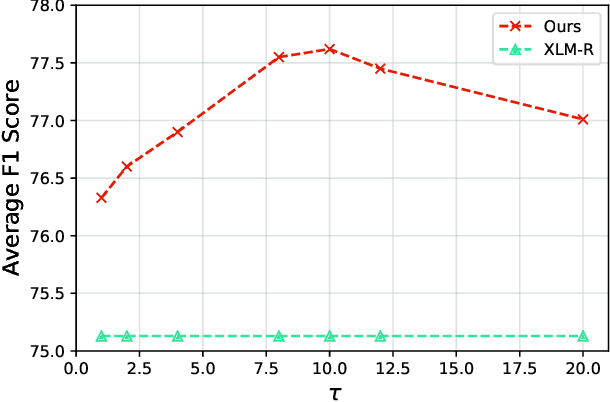
Cross-lingual Machine Reading Comprehension (xMRC) is challenging due to the lack of training data in low-resource languages. The recent approaches use training data only in a resource-rich language like English to fine-tune large-scale cross-lingual pre-trained language models. Due to the big difference between languages, a model fine-tuned only by a source language may not perform well for target languages. Interestingly, we observe that while the top-1 results predicted by the previous approaches may often fail to hit the ground-truth answers, the correct answers are often contained in the top-k predicted results. Based on this observation, we develop a two-stage approach to enhance the model performance. The first stage targets at recall: we design a hard-learning (HL) algorithm to maximize the likelihood that the top-k predictions contain the accurate answer. The second stage focuses on precision: an answer-aware contrastive learning (AA-CL) mechanism is developed to learn the fine difference between the accurate answer and other candidates. Our extensive experiments show that our model significantly outperforms a series of strong baselines on two cross-lingual MRC benchmark datasets.