 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal foundation models are better simulators of the human brain
Paper and Code
Aug 17, 2022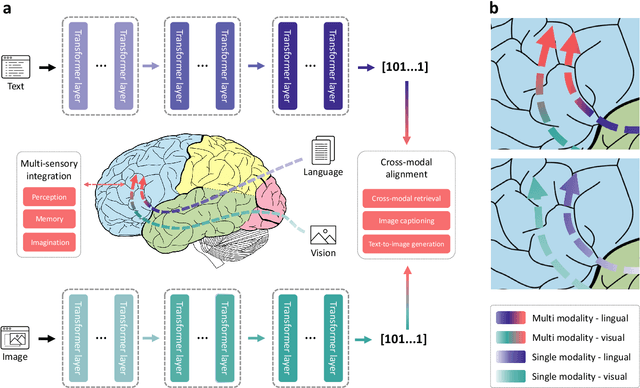
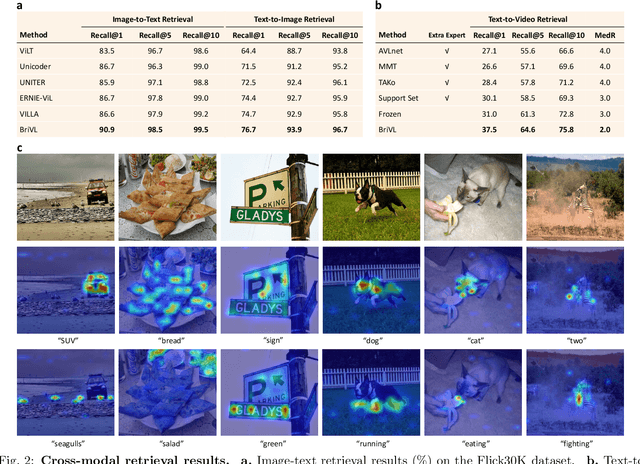

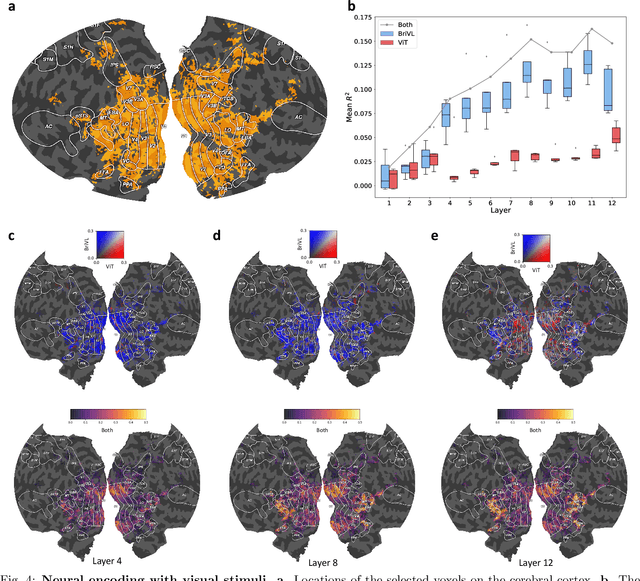
Multimodal learning, especially large-scale multimodal pre-training, has developed rapidly over the past few years and led to the greatest advances in artificial intelligence (AI). Despite its effectiveness, understanding the underlying mechanism of multimodal pre-training models still remains a grand challenge. Revealing the explainability of such models is likely to enable breakthroughs of novel learning paradigms in the AI field. To this end, given the multimodal nature of the human brain, we propose to explore the explainability of multimodal learning models with the aid of non-invasive brain imaging technologies such as functional magnetic resonance imaging (fMRI). Concretely, we first present a newly-designed multimodal foundation model pre-trained on 15 million image-text pairs, which has shown strong multimodal understanding and generalization abilities in a variety of cognitive downstream tasks. Further, from the perspective of neural encoding (based on our foundation model), we find that both visual and lingual encoders trained multimodally are more brain-like compared with unimodal ones. Particularly, we identify a number of brain regions where multimodally-trained encoders demonstrate better neural encoding performance. This is consistent with the findings in existing studies on exploring brain multi-sensory integration. Therefore, we believe that multimodal foundation models are more suitable tools for neuroscientists to study the multimodal signal processing mechanisms in the human brain. Our findings also demonstrate the potential of multimodal foundation models as ideal computational simulators to promote both AI-for-brain and brain-for-AI research.