 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Paper and Code
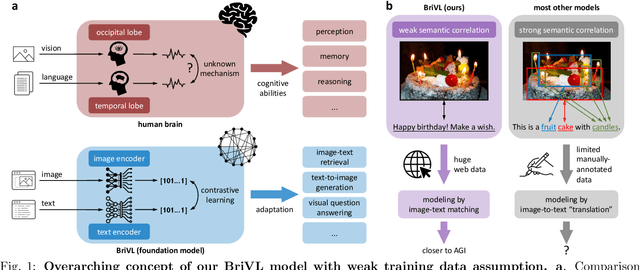


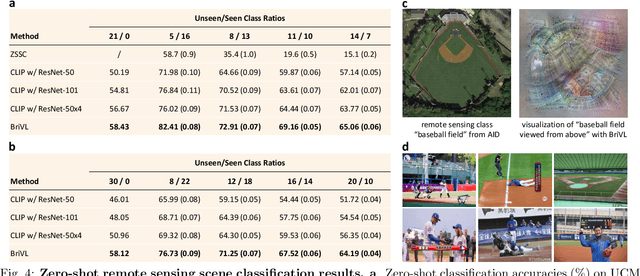
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).