 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytical Characterization of Sloppiness in Neural Networks: Insights from Linear Models
May 13, 2025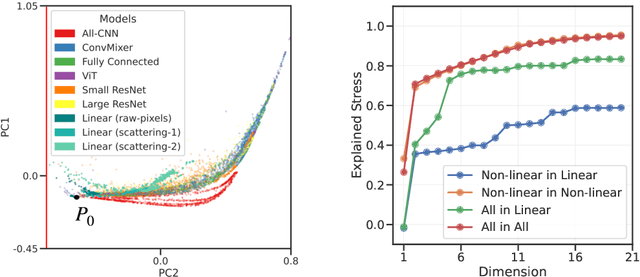
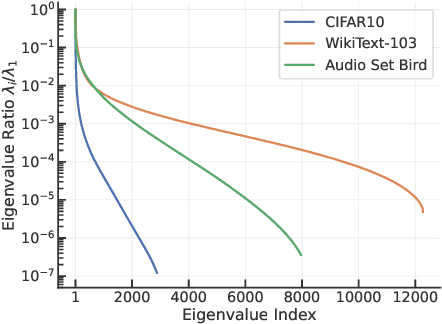
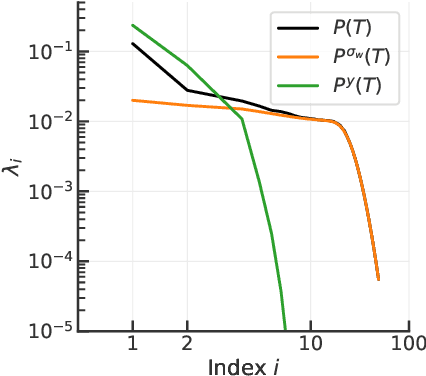
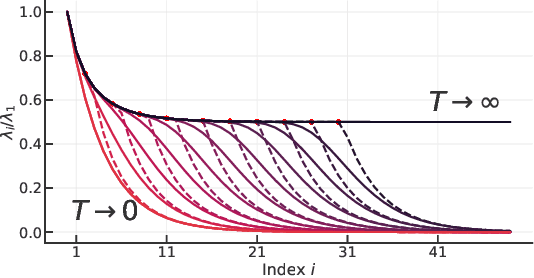
Recent experiments have shown that training trajectories of multiple deep neural networks with different architectures, optimization algorithms, hyper-parameter settings, and regularization methods evolve on a remarkably low-dimensional "hyper-ribbon-like" manifold in the space of probability distributions. Inspired by the similarities in the training trajectories of deep networks and linear networks, we analytically characterize this phenomenon for the latter. We show, using tools in dynamical systems theory, that the geometry of this low-dimensional manifold is controlled by (i) the decay rate of the eigenvalues of the input correlation matrix of the training data, (ii) the relative scale of the ground-truth output to the weights at the beginning of training, and (iii) the number of steps of gradient descent. By analytically computing and bounding the contributions of these quantities, we characterize phase boundaries of the region where hyper-ribbons are to be expected. We also extend our analysis to kernel machines and linear models that are trained with stochastic gradient descent.
The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold
May 02, 2023We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we reveal that the training process explores an effectively low-dimensional manifold. Networks with a wide range of architectures, sizes, trained using different optimization methods, regularization techniques, data augmentation techniques, and weight initializations lie on the same manifold in the prediction space. We study the details of this manifold to find that networks with different architectures follow distinguishable trajectories but other factors have a minimal influence; larger networks train along a similar manifold as that of smaller networks, just faster; and networks initialized at very different parts of the prediction space converge to the solution along a similar manifold.
A picture of the space of typical learnable tasks
Oct 31, 2022We develop a technique to analyze representations learned by deep networks when they are trained on different tasks using supervised, meta- and contrastive learning. We develop a technique to visualize such representations using an isometric embedding of the space of probabilistic models into a lower-dimensional space, i.e., one that preserves pairwise distances. We discover the following surprising phenomena that shed light upon the structure in the space of learnable tasks: (1) the manifold of probabilistic models trained on different tasks using different representation learning methods is effectively low-dimensional; (2) supervised learning on one task results in a surprising amount of progress on seemingly dissimilar tasks; progress on other tasks is larger if the training task has diverse classes; (3) the structure of the space of tasks indicated by our analysis is consistent with parts of the Wordnet phylogenetic tree; (4) fine-tuning a model upon a sub-task does not change the representation much if the model was trained for a large number of epochs; (5) episodic meta-learning algorithms fit similar models eventually as that of supervised learning, even if the two traverse different trajectories during training; (6) contrastive learning methods trained on different datasets learn similar representations. We use classification tasks constructed from the CIFAR-10 and Imagenet datasets to study these phenomena.