 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning
Aug 08, 2025Long-context inference for Large Language Models (LLMs) is heavily limited by high computational demands. While several existing methods optimize attention computation, they still process the full set of hidden states at each layer, limiting overall efficiency. In this work, we propose SlimInfer, an innovative framework that aims to accelerate inference by directly pruning less critical prompt tokens during the forward pass. Our key insight is an information diffusion phenomenon: As information from critical tokens propagates through layers, it becomes distributed across the entire sequence. This diffusion process suggests that LLMs can maintain their semantic integrity when excessive tokens, even including these critical ones, are pruned in hidden states. Motivated by this, SlimInfer introduces a dynamic fine-grained pruning mechanism that accurately removes redundant tokens of hidden state at intermediate layers. This layer-wise pruning naturally enables an asynchronous KV cache manager that prefetches required token blocks without complex predictors, reducing both memory usage and I/O costs. Extensive experiments show that SlimInfer can achieve up to $\mathbf{2.53\times}$ time-to-first-token (TTFT) speedup and $\mathbf{1.88\times}$ end-to-end latency reduction for LLaMA3.1-8B-Instruct on a single RTX 4090, without sacrificing performance on LongBench. Our code will be released upon acceptance.
An Effective Gram Matrix Characterizes Generalization in Deep Networks
Apr 24, 2025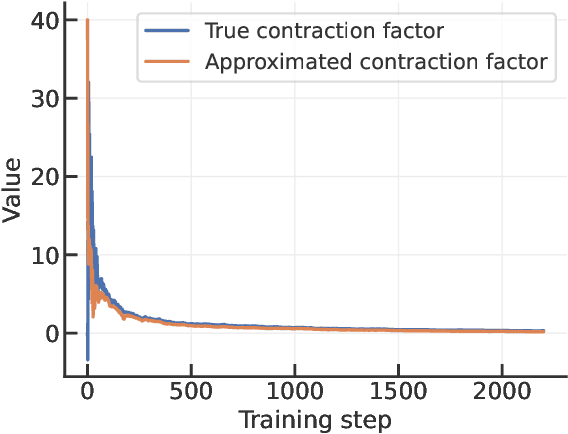

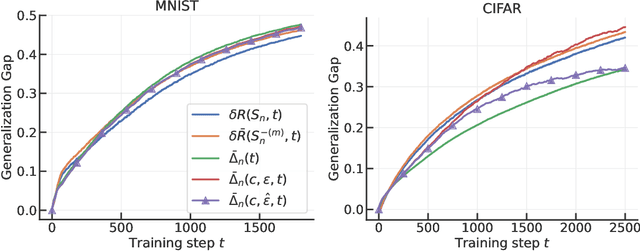
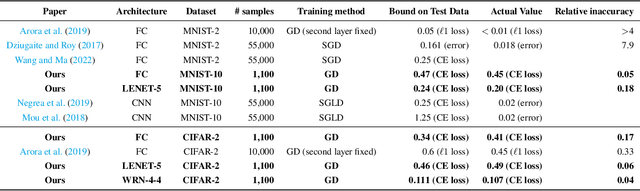
We derive a differential equation that governs the evolution of the generalization gap when a deep network is trained by gradient descent. This differential equation is controlled by two quantities, a contraction factor that brings together trajectories corresponding to slightly different datasets, and a perturbation factor that accounts for them training on different datasets. We analyze this differential equation to compute an ``effective Gram matrix'' that characterizes the generalization gap after training in terms of the alignment between this Gram matrix and a certain initial ``residual''. Empirical evaluations on image classification datasets indicate that this analysis can predict the test loss accurately. Further, at any point during training, the residual predominantly lies in the subspace of the effective Gram matrix with the smallest eigenvalues. This indicates that the training process is benign, i.e., it does not lead to significant deterioration of the generalization gap (which is zero at initialization). The alignment between the effective Gram matrix and the residual is different for different datasets and architectures. The match/mismatch of the data and the architecture is primarily responsible for good/bad generalization.
Prospective Learning: Learning for a Dynamic Future
Oct 31, 2024In real-world applications, the distribution of the data, and our goals, evolve over time. The prevailing theoretical framework for studying machine learning, namely probably approximately correct (PAC) learning, largely ignores time. As a consequence, existing strategies to address the dynamic nature of data and goals exhibit poor real-world performance. This paper develops a theoretical framework called "Prospective Learning" that is tailored for situations when the optimal hypothesis changes over time. In PAC learning, empirical risk minimization (ERM) is known to be consistent. We develop a learner called Prospective ERM, which returns a sequence of predictors that make predictions on future data. We prove that the risk of prospective ERM converges to the Bayes risk under certain assumptions on the stochastic process generating the data. Prospective ERM, roughly speaking, incorporates time as an input in addition to the data. We show that standard ERM as done in PAC learning, without incorporating time, can result in failure to learn when distributions are dynamic. Numerical experiments illustrate that prospective ERM can learn synthetic and visual recognition problems constructed from MNIST and CIFAR-10.
The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold
May 02, 2023We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we reveal that the training process explores an effectively low-dimensional manifold. Networks with a wide range of architectures, sizes, trained using different optimization methods, regularization techniques, data augmentation techniques, and weight initializations lie on the same manifold in the prediction space. We study the details of this manifold to find that networks with different architectures follow distinguishable trajectories but other factors have a minimal influence; larger networks train along a similar manifold as that of smaller networks, just faster; and networks initialized at very different parts of the prediction space converge to the solution along a similar manifold.
A picture of the space of typical learnable tasks
Oct 31, 2022We develop a technique to analyze representations learned by deep networks when they are trained on different tasks using supervised, meta- and contrastive learning. We develop a technique to visualize such representations using an isometric embedding of the space of probabilistic models into a lower-dimensional space, i.e., one that preserves pairwise distances. We discover the following surprising phenomena that shed light upon the structure in the space of learnable tasks: (1) the manifold of probabilistic models trained on different tasks using different representation learning methods is effectively low-dimensional; (2) supervised learning on one task results in a surprising amount of progress on seemingly dissimilar tasks; progress on other tasks is larger if the training task has diverse classes; (3) the structure of the space of tasks indicated by our analysis is consistent with parts of the Wordnet phylogenetic tree; (4) fine-tuning a model upon a sub-task does not change the representation much if the model was trained for a large number of epochs; (5) episodic meta-learning algorithms fit similar models eventually as that of supervised learning, even if the two traverse different trajectories during training; (6) contrastive learning methods trained on different datasets learn similar representations. We use classification tasks constructed from the CIFAR-10 and Imagenet datasets to study these phenomena.