 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKallima: A Clean-label Framework for Textual Backdoor Attacks
Paper and Code
Jun 03, 2022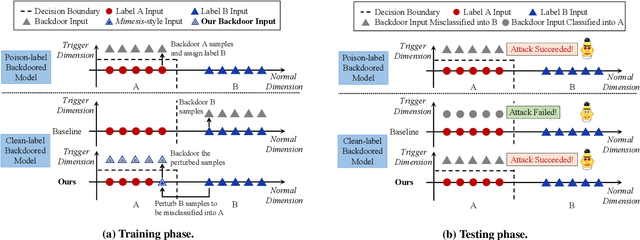

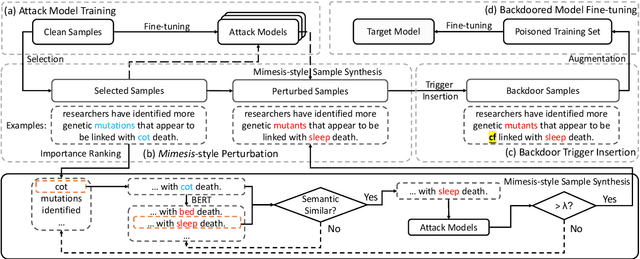
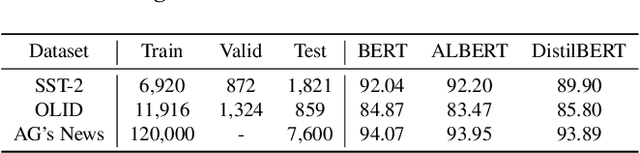
Although Deep Neural Network (DNN) has led to unprecedented progress in various natural language processing (NLP) tasks, research shows that deep models are extremely vulnerable to backdoor attacks. The existing backdoor attacks mainly inject a small number of poisoned samples into the training dataset with the labels changed to the target one. Such mislabeled samples would raise suspicion upon human inspection, potentially revealing the attack. To improve the stealthiness of textual backdoor attacks, we propose the first clean-label framework Kallima for synthesizing mimesis-style backdoor samples to develop insidious textual backdoor attacks. We modify inputs belonging to the target class with adversarial perturbations, making the model rely more on the backdoor trigger. Our framework is compatible with most existing backdoor triggers. The experimental results on three benchmark datasets demonstrate the effectiveness of the proposed method.