 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecutable Counterfactuals: Improving LLMs' Causal Reasoning Through Code
Oct 02, 2025Counterfactual reasoning, a hallmark of intelligence, consists of three steps: inferring latent variables from observations (abduction), constructing alternatives (interventions), and predicting their outcomes (prediction). This skill is essential for advancing LLMs' causal understanding and expanding their applications in high-stakes domains such as scientific research. However, existing efforts in assessing LLM's counterfactual reasoning capabilities tend to skip the abduction step, effectively reducing to interventional reasoning and leading to overestimation of LLM performance. To address this, we introduce executable counterfactuals, a novel framework that operationalizes causal reasoning through code and math problems. Our framework explicitly requires all three steps of counterfactual reasoning and enables scalable synthetic data creation with varying difficulty, creating a frontier for evaluating and improving LLM's reasoning. Our results reveal substantial drop in accuracy (25-40%) from interventional to counterfactual reasoning for SOTA models like o4-mini and Claude-4-Sonnet. To address this gap, we construct a training set comprising counterfactual code problems having if-else condition and test on out-of-domain code structures (e.g. having while-loop); we also test whether a model trained on code would generalize to counterfactual math word problems. While supervised finetuning on stronger models' reasoning traces improves in-domain performance of Qwen models, it leads to a decrease in accuracy on OOD tasks such as counterfactual math problems. In contrast, reinforcement learning induces the core cognitive behaviors and generalizes to new domains, yielding gains over the base model on both code (improvement of 1.5x-2x) and math problems. Analysis of the reasoning traces reinforces these findings and highlights the promise of RL for improving LLMs' counterfactual reasoning.
The Best Instruction-Tuning Data are Those That Fit
Feb 07, 2025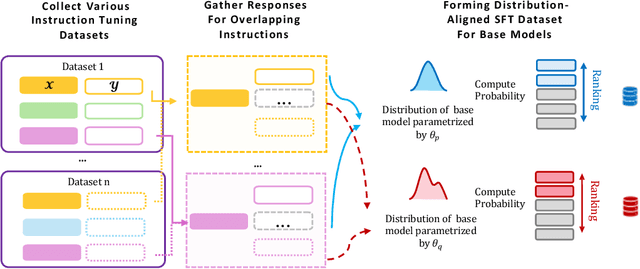
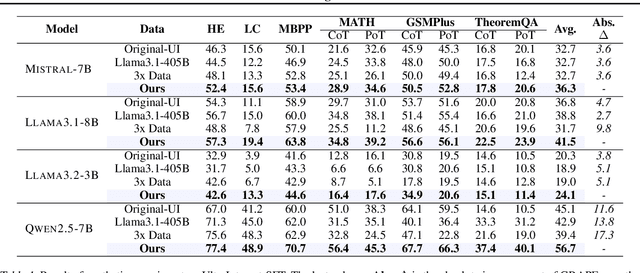
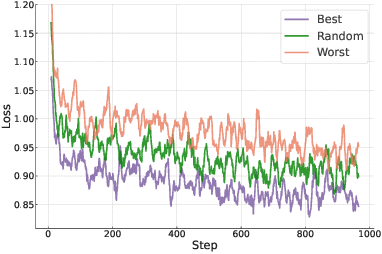
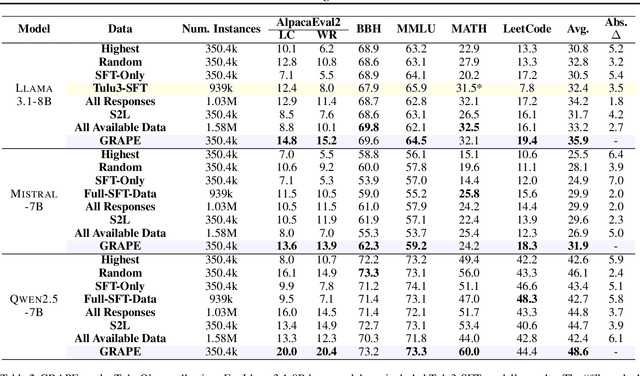
High-quality supervised fine-tuning (SFT) data are crucial for eliciting strong capabilities from pretrained large language models (LLMs). Typically, instructions are paired with multiple responses sampled from other LLMs, which are often out of the distribution of the target model to be fine-tuned. This, at scale, can lead to diminishing returns and even hurt the models' performance and robustness. We propose **GRAPE**, a novel SFT framework that accounts for the unique characteristics of the target model. For each instruction, it gathers responses from various LLMs and selects the one with the highest probability measured by the target model, indicating that it aligns most closely with the target model's pretrained distribution; it then proceeds with standard SFT training. We first evaluate GRAPE with a controlled experiment, where we sample various solutions for each question in UltraInteract from multiple models and fine-tune commonly used LMs like LLaMA3.1-8B, Mistral-7B, and Qwen2.5-7B on GRAPE-selected data. GRAPE significantly outperforms strong baselines, including distilling from the strongest model with an absolute gain of up to 13.8%, averaged across benchmarks, and training on 3x more data with a maximum performance improvement of 17.3%. GRAPE's strong performance generalizes to realistic settings. We experiment with the post-training data used for Tulu3 and Olmo-2. GRAPE outperforms strong baselines trained on 4.5 times more data by 6.1% and a state-of-the-art data selection approach by 3% on average performance. Remarkably, using 1/3 of the data and half the number of epochs, GRAPE enables LLaMA3.1-8B to surpass the performance of Tulu3-SFT by 3.5%.
Improving Influence-based Instruction Tuning Data Selection for Balanced Learning of Diverse Capabilities
Jan 21, 2025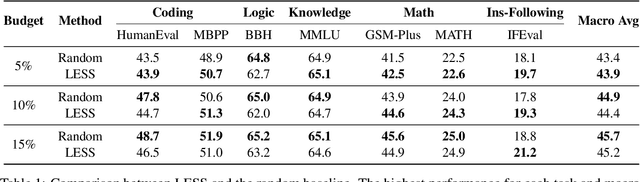
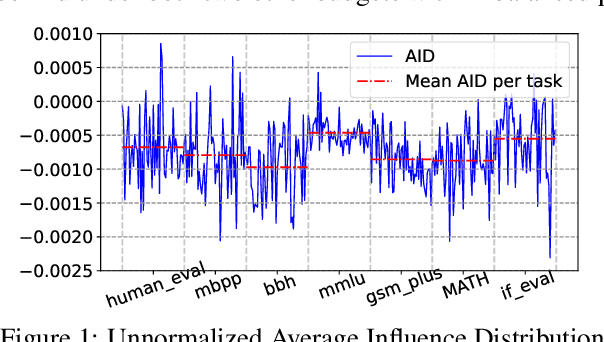
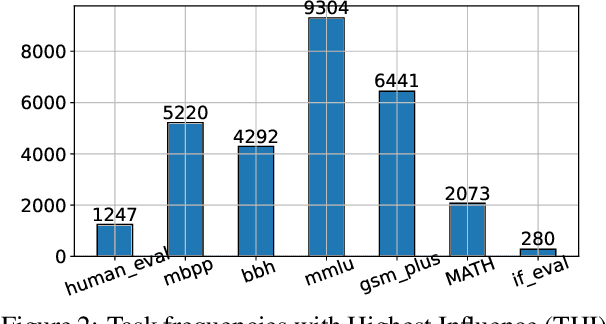
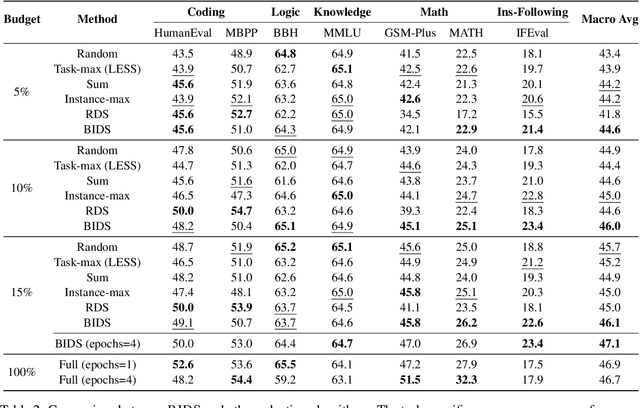
Selecting appropriate training data is crucial for effective instruction fine-tuning of large language models (LLMs), which aims to (1) elicit strong capabilities, and (2) achieve balanced performance across a diverse range of tasks. Influence-based methods show promise in achieving (1) by estimating the contribution of each training example to the model's predictions, but often struggle with (2). Our systematic investigation reveals that this underperformance can be attributed to an inherent bias where certain tasks intrinsically have greater influence than others. As a result, data selection is often biased towards these tasks, not only hurting the model's performance on others but also, counterintuitively, harms performance on these high-influence tasks themselves. As a remedy, we propose BIDS, a Balanced and Influential Data Selection algorithm. BIDS first normalizes influence scores of the training data, and then iteratively balances data selection by choosing the training example with the highest influence on the most underrepresented task. Experiments with both Llama-3 and Mistral-v0.3 on seven benchmarks spanning five diverse capabilities show that BIDS consistently outperforms both state-of-the-art influence-based algorithms and other non-influence-based selection frameworks. Surprisingly, training on a 15% subset selected by BIDS can even outperform full-dataset training with a much more balanced performance. Our analysis further highlights the importance of both instance-level normalization and iterative optimization of selected data for balanced learning of diverse capabilities.