 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Best Instruction-Tuning Data are Those That Fit
Paper and Code
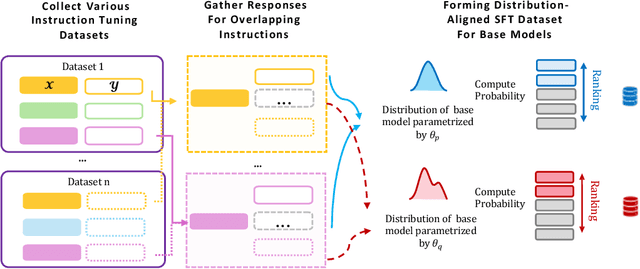
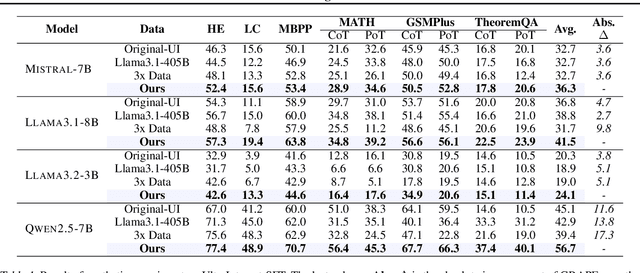
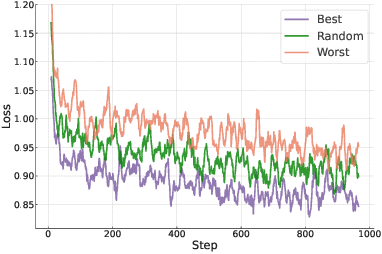
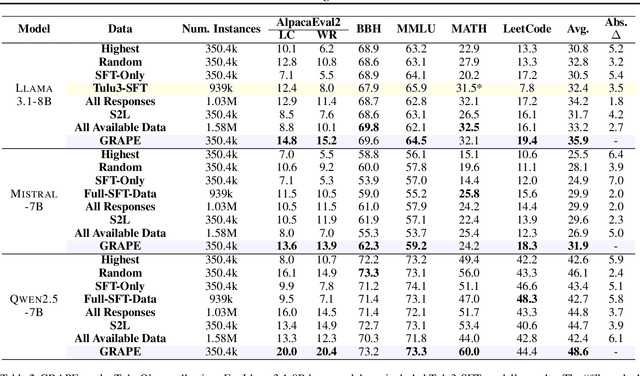
High-quality supervised fine-tuning (SFT) data are crucial for eliciting strong capabilities from pretrained large language models (LLMs). Typically, instructions are paired with multiple responses sampled from other LLMs, which are often out of the distribution of the target model to be fine-tuned. This, at scale, can lead to diminishing returns and even hurt the models' performance and robustness. We propose **GRAPE**, a novel SFT framework that accounts for the unique characteristics of the target model. For each instruction, it gathers responses from various LLMs and selects the one with the highest probability measured by the target model, indicating that it aligns most closely with the target model's pretrained distribution; it then proceeds with standard SFT training. We first evaluate GRAPE with a controlled experiment, where we sample various solutions for each question in UltraInteract from multiple models and fine-tune commonly used LMs like LLaMA3.1-8B, Mistral-7B, and Qwen2.5-7B on GRAPE-selected data. GRAPE significantly outperforms strong baselines, including distilling from the strongest model with an absolute gain of up to 13.8%, averaged across benchmarks, and training on 3x more data with a maximum performance improvement of 17.3%. GRAPE's strong performance generalizes to realistic settings. We experiment with the post-training data used for Tulu3 and Olmo-2. GRAPE outperforms strong baselines trained on 4.5 times more data by 6.1% and a state-of-the-art data selection approach by 3% on average performance. Remarkably, using 1/3 of the data and half the number of epochs, GRAPE enables LLaMA3.1-8B to surpass the performance of Tulu3-SFT by 3.5%.