 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions
Paper and Code
Jul 28, 2022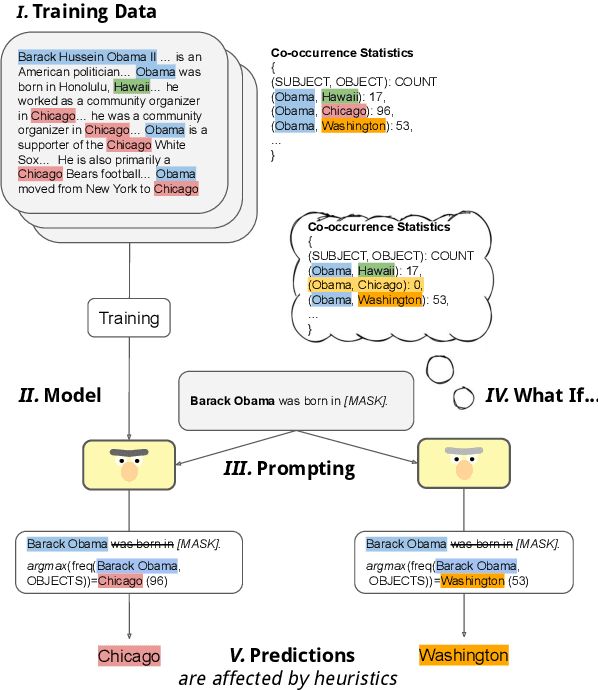

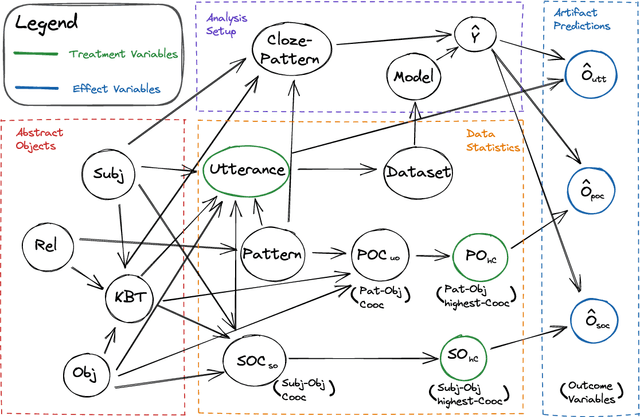

Large amounts of training data are one of the major reasons for the high performance of state-of-the-art NLP models. But what exactly in the training data causes a model to make a certain prediction? We seek to answer this question by providing a language for describing how training data influences predictions, through a causal framework. Importantly, our framework bypasses the need to retrain expensive models and allows us to estimate causal effects based on observational data alone. Addressing the problem of extracting factual knowledge from pretrained language models (PLMs), we focus on simple data statistics such as co-occurrence counts and show that these statistics do influence the predictions of PLMs, suggesting that such models rely on shallow heuristics. Our causal framework and our results demonstrate the importance of studying datasets and the benefits of causality for understanding NLP models.