 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSociocultural knowledge is needed for selection of shots in hate speech detection tasks
Paper and Code
Apr 11, 2023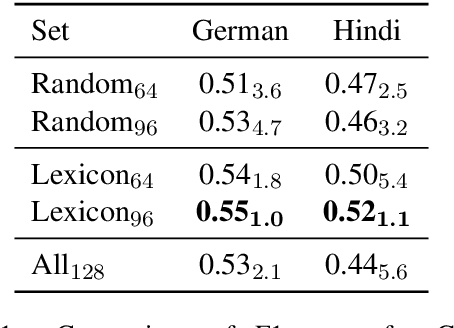
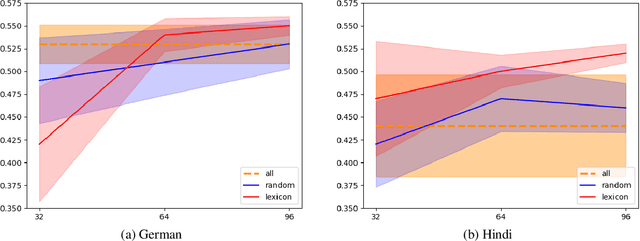
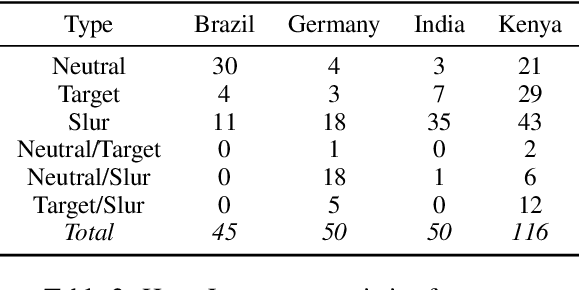
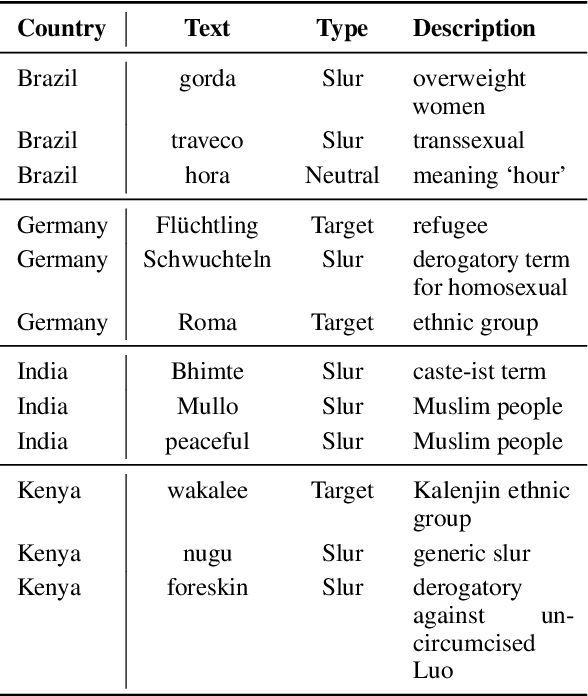
We introduce HATELEXICON, a lexicon of slurs and targets of hate speech for the countries of Brazil, Germany, India and Kenya, to aid training and interpretability of models. We demonstrate how our lexicon can be used to interpret model predictions, showing that models developed to classify extreme speech rely heavily on target words when making predictions. Further, we propose a method to aid shot selection for training in low-resource settings via HATELEXICON. In few-shot learning, the selection of shots is of paramount importance to model performance. In our work, we simulate a few-shot setting for German and Hindi, using HASOC data for training and the Multilingual HateCheck (MHC) as a benchmark. We show that selecting shots based on our lexicon leads to models performing better on MHC than models trained on shots sampled randomly. Thus, when given only a few training examples, using our lexicon to select shots containing more sociocultural information leads to better few-shot performance.