 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT Cannot Align Characters
Paper and Code
Sep 20, 2021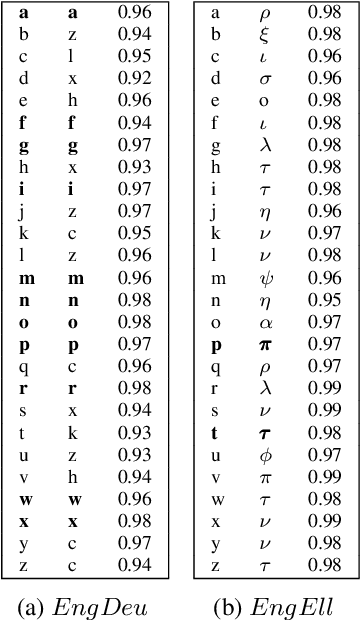
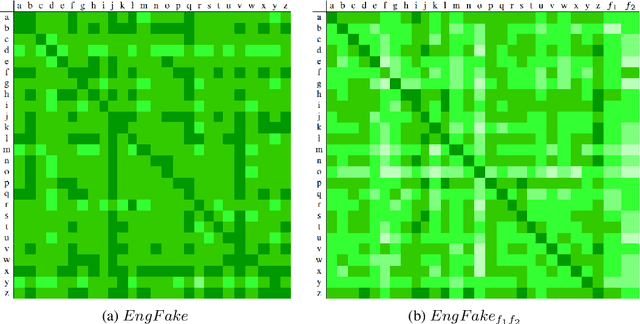
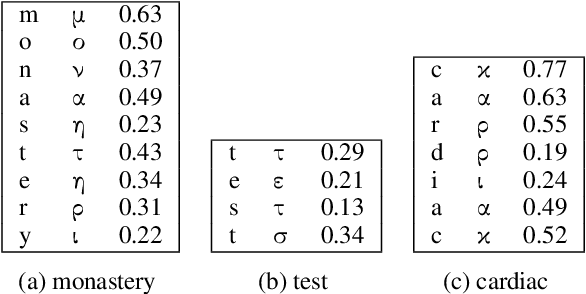
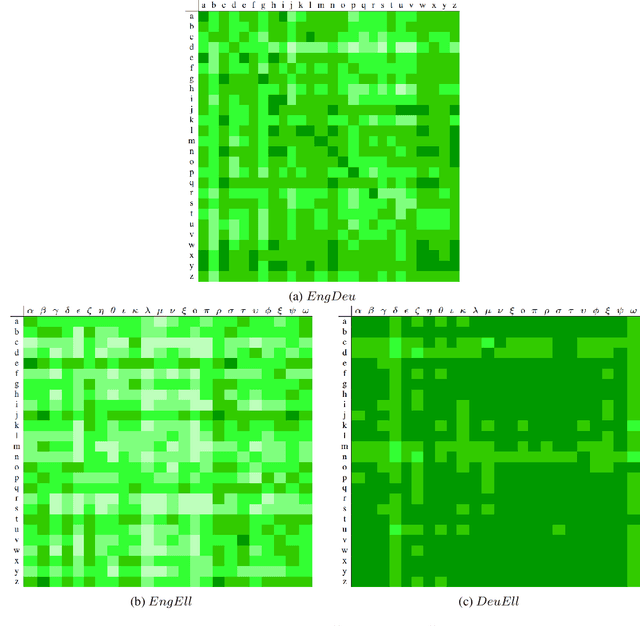
In previous work, it has been shown that BERT can adequately align cross-lingual sentences on the word level. Here we investigate whether BERT can also operate as a char-level aligner. The languages examined are English, Fake-English, German and Greek. We show that the closer two languages are, the better BERT can align them on the character level. BERT indeed works well in English to Fake-English alignment, but this does not generalize to natural languages to the same extent. Nevertheless, the proximity of two languages does seem to be a factor. English is more related to German than to Greek and this is reflected in how well BERT aligns them; English to German is better than English to Greek. We examine multiple setups and show that the similarity matrices for natural languages show weaker relations the further apart two languages are.