 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models More Empathetic than Humans?
Jun 07, 2024



With the emergence of large language models (LLMs), investigating if they can surpass humans in areas such as emotion recognition and empathetic responding has become a focal point of research. This paper presents a comprehensive study exploring the empathetic responding capabilities of four state-of-the-art LLMs: GPT-4, LLaMA-2-70B-Chat, Gemini-1.0-Pro, and Mixtral-8x7B-Instruct in comparison to a human baseline. We engaged 1,000 participants in a between-subjects user study, assessing the empathetic quality of responses generated by humans and the four LLMs to 2,000 emotional dialogue prompts meticulously selected to cover a broad spectrum of 32 distinct positive and negative emotions. Our findings reveal a statistically significant superiority of the empathetic responding capability of LLMs over humans. GPT-4 emerged as the most empathetic, marking approximately 31% increase in responses rated as "Good" compared to the human benchmark. It was followed by LLaMA-2, Mixtral-8x7B, and Gemini-Pro, which showed increases of approximately 24%, 21%, and 10% in "Good" ratings, respectively. We further analyzed the response ratings at a finer granularity and discovered that some LLMs are significantly better at responding to specific emotions compared to others. The suggested evaluation framework offers a scalable and adaptable approach for assessing the empathy of new LLMs, avoiding the need to replicate this study's findings in future research.
Is ChatGPT More Empathetic than Humans?
Feb 22, 2024



This paper investigates the empathetic responding capabilities of ChatGPT, particularly its latest iteration, GPT-4, in comparison to human-generated responses to a wide range of emotional scenarios, both positive and negative. We employ a rigorous evaluation methodology, involving a between-groups study with 600 participants, to evaluate the level of empathy in responses generated by humans and ChatGPT. ChatGPT is prompted in two distinct ways: a standard approach and one explicitly detailing empathy's cognitive, affective, and compassionate counterparts. Our findings indicate that the average empathy rating of responses generated by ChatGPT exceeds those crafted by humans by approximately 10%. Additionally, instructing ChatGPT to incorporate a clear understanding of empathy in its responses makes the responses align approximately 5 times more closely with the expectations of individuals possessing a high degree of empathy, compared to human responses. The proposed evaluation framework serves as a scalable and adaptable framework to assess the empathetic capabilities of newer and updated versions of large language models, eliminating the need to replicate the current study's results in future research.
Use of a Taxonomy of Empathetic Response Intents to Control and Interpret Empathy in Neural Chatbots
May 17, 2023



A recent trend in the domain of open-domain conversational agents is enabling them to converse empathetically to emotional prompts. Current approaches either follow an end-to-end approach or condition the responses on similar emotion labels to generate empathetic responses. But empathy is a broad concept that refers to the cognitive and emotional reactions of an individual to the observed experiences of another and it is more complex than mere mimicry of emotion. Hence, it requires identifying complex human conversational strategies and dynamics in addition to generic emotions to control and interpret empathetic responding capabilities of chatbots. In this work, we make use of a taxonomy of eight empathetic response intents in addition to generic emotion categories in building a dialogue response generation model capable of generating empathetic responses in a controllable and interpretable manner. It consists of two modules: 1) a response emotion/intent prediction module; and 2) a response generation module. We propose several rule-based and neural approaches to predict the next response's emotion/intent and generate responses conditioned on these predicted emotions/intents. Automatic and human evaluation results emphasize the importance of the use of the taxonomy of empathetic response intents in producing more diverse and empathetically more appropriate responses than end-to-end models.
Boosting Distress Support Dialogue Responses with Motivational Interviewing Strategy
May 17, 2023



AI-driven chatbots have become an emerging solution to address psychological distress. Due to the lack of psychotherapeutic data, researchers use dialogues scraped from online peer support forums to train them. But since the responses in such platforms are not given by professionals, they contain both conforming and non-conforming responses. In this work, we attempt to recognize these conforming and non-conforming response types present in online distress-support dialogues using labels adapted from a well-established behavioral coding scheme named Motivational Interviewing Treatment Integrity (MITI) code and show how some response types could be rephrased into a more MI adherent form that can, in turn, enable chatbot responses to be more compliant with the MI strategy. As a proof of concept, we build several rephrasers by fine-tuning Blender and GPT3 to rephrase MI non-adherent "Advise without permission" responses into "Advise with permission". We show how this can be achieved with the construction of pseudo-parallel corpora avoiding costs for human labor. Through automatic and human evaluation we show that in the presence of less training data, techniques such as prompting and data augmentation can be used to produce substantially good rephrasings that reflect the intended style and preserve the content of the original text.
Fine-grained Emotion and Intent Learning in Movie Dialogues
Dec 25, 2020

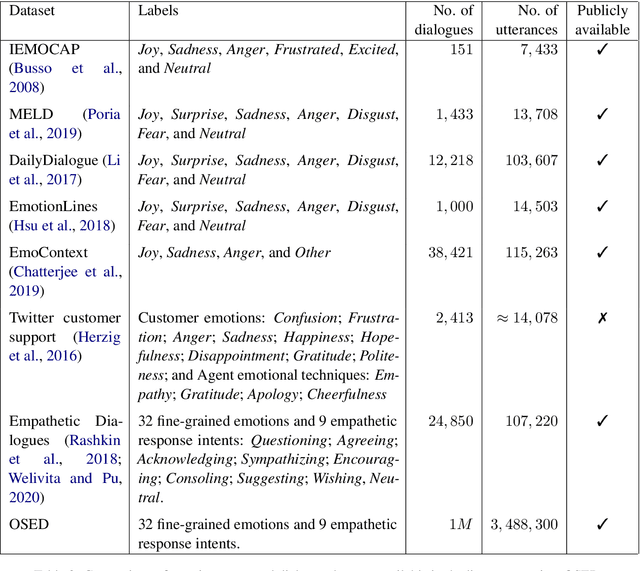
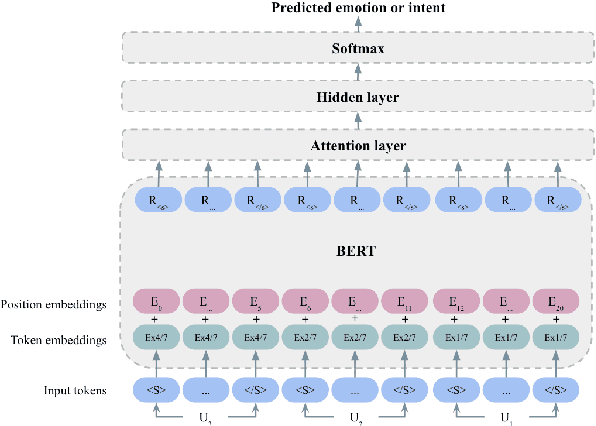
We propose a novel large-scale emotional dialogue dataset, consisting of 1M dialogues retrieved from the OpenSubtitles corpus and annotated with 32 emotions and 9 empathetic response intents using a BERT-based fine-grained dialogue emotion classifier. This work explains the complex pipeline used to preprocess movie subtitles and select good movie dialogues to annotate. We also describe the semi-supervised learning process followed to train a fine-grained emotion classifier to annotate these dialogues. Despite the large set of labels, our dialogue emotion classifier achieved an accuracy of $65\%$ and was used to annotate 1M emotional movie dialogues from OpenSubtitles. This scale of emotional dialogue classification has never been attempted before, both in terms of dataset size and fine-grained emotion and intent categories. Visualization techniques used to analyze the quality of the resultant dataset suggest that it conforms to the patterns of human social interaction.
A Taxonomy of Empathetic Response Intents in Human Social Conversations
Dec 07, 2020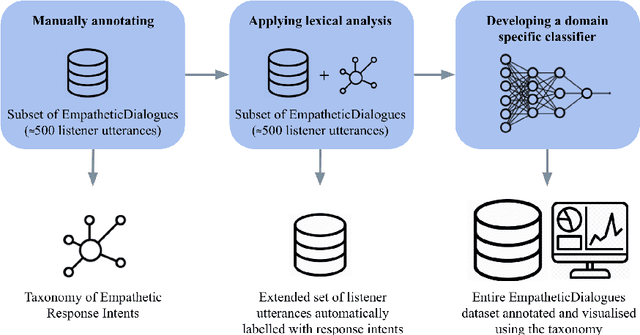

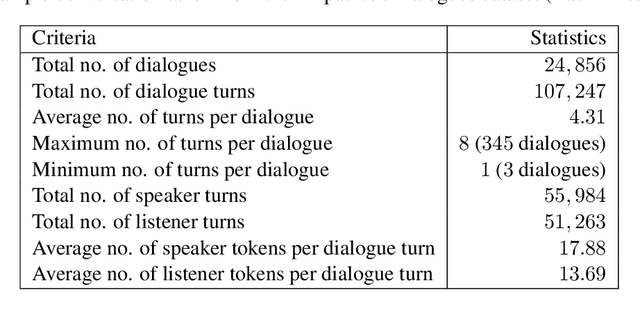
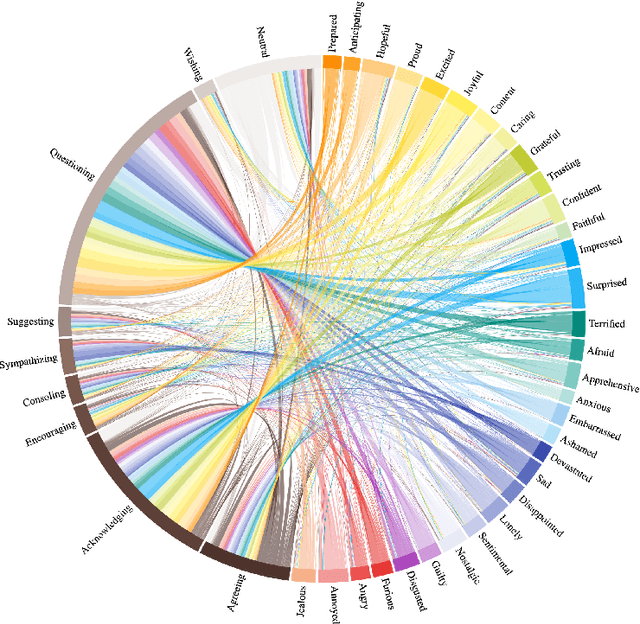
Open-domain conversational agents or chatbots are becoming increasingly popular in the natural language processing community. One of the challenges is enabling them to converse in an empathetic manner. Current neural response generation methods rely solely on end-to-end learning from large scale conversation data to generate dialogues. This approach can produce socially unacceptable responses due to the lack of large-scale quality data used to train the neural models. However, recent work has shown the promise of combining dialogue act/intent modelling and neural response generation. This hybrid method improves the response quality of chatbots and makes them more controllable and interpretable. A key element in dialog intent modelling is the development of a taxonomy. Inspired by this idea, we have manually labeled 500 response intents using a subset of a sizeable empathetic dialogue dataset (25K dialogues). Our goal is to produce a large-scale taxonomy for empathetic response intents. Furthermore, using lexical and machine learning methods, we automatically analysed both speaker and listener utterances of the entire dataset with identified response intents and 32 emotion categories. Finally, we use information visualization methods to summarize emotional dialogue exchange patterns and their temporal progression. These results reveal novel and important empathy patterns in human-human open-domain conversations and can serve as heuristics for hybrid approaches.