 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline vs Offline: A Comparative Study of First-Party and Third-Party Evaluations of Social Chatbots
Sep 12, 2024This paper explores the efficacy of online versus offline evaluation methods in assessing conversational chatbots, specifically comparing first-party direct interactions with third-party observational assessments. By extending a benchmarking dataset of user dialogs with empathetic chatbots with offline third-party evaluations, we present a systematic comparison between the feedback from online interactions and the more detached offline third-party evaluations. Our results reveal that offline human evaluations fail to capture the subtleties of human-chatbot interactions as effectively as online assessments. In comparison, automated third-party evaluations using a GPT-4 model offer a better approximation of first-party human judgments given detailed instructions. This study highlights the limitations of third-party evaluations in grasping the complexities of user experiences and advocates for the integration of direct interaction feedback in conversational AI evaluation to enhance system development and user satisfaction.
Approximating Human Evaluation of Social Chatbots with Prompting
Apr 11, 2023Once powerful conversational models have become available for a wide audience, users started actively engaging in social interactions with this technology. Such unprecedented interaction experiences may pose considerable social and psychological risks to the users unless the technology is properly controlled. This creates an urgent need for scalable and robust evaluation metrics for conversational chatbots. Existing automatic evaluation metrics usually focus on objective quality measures and disregard subjective perceptions of social dimensions. Moreover, most of these approaches operate on pre-produced dialogs from available benchmark corpora, which implies human involvement for preparing the material for evaluation and, thus, impeded scalability of the metrics. To address this limitation, we propose to make use of the emerging large language models (LLMs) from the GPT-family and describe a new framework allowing to conduct dialog system evaluation with prompting. With this framework, we are able to achieve full automation of the evaluation pipeline and reach impressive correlation with the human judgement (up to Pearson r=0.95 on system level). The underlying concept is to collect synthetic chat logs of evaluated bots with a LLM in the other-play setting, where LLM is carefully conditioned to follow a specific scenario. We further explore different prompting approaches to produce evaluation scores with the same LLM. The best-performing prompts, containing few-show demonstrations and instructions, show outstanding performance on the tested dataset and demonstrate the ability to generalize to other dialog corpora.
A Multi-Turn Emotionally Engaging Dialog Model
Sep 14, 2019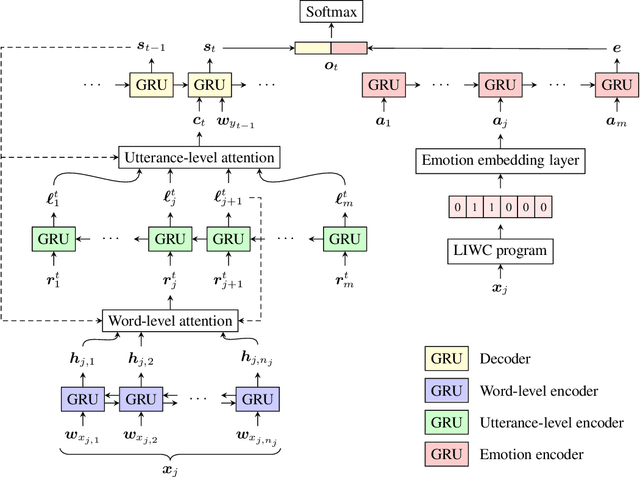


Open-domain dialog systems (also known as chatbots) have increasingly drawn attention in natural language processing. Some of the recent work aims at incorporating affect information into sequence-to-sequence neural dialog modeling, making the response emotionally richer, while others use hand-crafted rules to determine the desired emotion response. However, they do not explicitly learn the subtle emotional interactions captured in human dialogs. In this paper, we propose a multi-turn dialog system aimed at learning and generating emotional responses that so far only humans know how to do. Compared with two baseline models, offline experiments show that our method performs the best in perplexity scores. Further human evaluations confirm that our chatbot can keep track of the conversation context and generate emotionally more appropriate responses while performing equally well on grammar.