 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWybeCoder: Verified Imperative Code Generation
Mar 31, 2026Recent progress in large language models (LLMs) has advanced automatic code generation and formal theorem proving, yet software verification has not seen the same improvement. To address this gap, we propose WybeCoder, an agentic code verification framework that enables prove-as-you-generate development where code, invariants, and proofs co-evolve. It builds on a recent framework that combines automatic verification condition generation and SMT solvers with interactive proofs in Lean. To enable systematic evaluation, we translate two benchmarks for functional verification in Lean, Verina and Clever, to equivalent imperative code specifications. On complex algorithms such as Heapsort, we observe consistent performance improvements by scaling our approach, synthesizing dozens of valid invariants and dispatching of dozens of subgoals, resulting in hundreds of lines of verified code, overcoming plateaus reported in previous works. Our best system solves 74% of Verina tasks and 62% of Clever tasks at moderate compute budgets, significantly surpassing previous evaluations and paving a path to automated construction of large-scale datasets of verified imperative code.
Retrofitting (Large) Language Models with Dynamic Tokenization
Nov 27, 2024Current language models (LMs) use a fixed, static subword tokenizer. This choice, often taken for granted, typically results in degraded efficiency and capabilities in languages other than English, and makes it challenging to apply LMs to new domains or languages. To address these issues, we propose retrofitting LMs with dynamic tokenization: a way to dynamically decide on token boundaries based on the input text. For encoder-style models, we introduce a subword-merging algorithm inspired by byte-pair encoding (BPE), but at a batch level. We merge frequent subword sequences in a batch, then apply a pretrained embedding-prediction hypernetwork to compute the token embeddings on-the-fly. When applied with word-level boundaries, this on average reduces token sequence lengths by >20% across 14 languages on XNLI with XLM-R while degrading its task performance by less than 2%. For decoder-style models, we apply dynamic tokenization in two ways: 1) for prefilling, maintaining performance of Mistral-7B almost completely with up to 40% sequence reduction - relative to the word-level; and 2) via an approximate nearest neighbor index, achieving fast generation with a one million token vocabulary, demonstrating scalability to even larger, dynamic vocabularies. Overall, our findings show that dynamic tokenization substantially improves inference speed and promotes fairness across languages, making a leap towards overcoming the limitations of static tokenization and enabling more equitable and adaptable LMs.
Learning to Generate and Evaluate Fact-checking Explanations with Transformers
Oct 21, 2024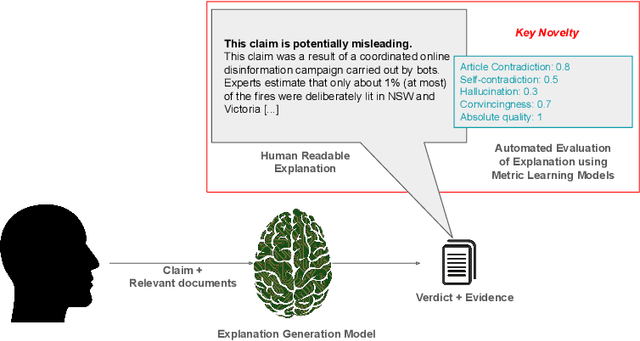

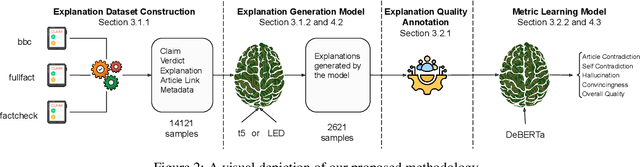
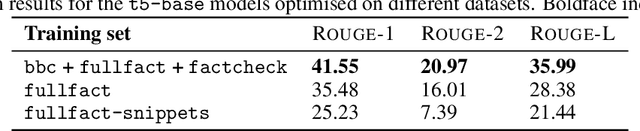
In an era increasingly dominated by digital platforms, the spread of misinformation poses a significant challenge, highlighting the need for solutions capable of assessing information veracity. Our research contributes to the field of Explainable Artificial Antelligence (XAI) by developing transformer-based fact-checking models that contextualise and justify their decisions by generating human-accessible explanations. Importantly, we also develop models for automatic evaluation of explanations for fact-checking verdicts across different dimensions such as \texttt{(self)-contradiction}, \texttt{hallucination}, \texttt{convincingness} and \texttt{overall quality}. By introducing human-centred evaluation methods and developing specialised datasets, we emphasise the need for aligning Artificial Intelligence (AI)-generated explanations with human judgements. This approach not only advances theoretical knowledge in XAI but also holds practical implications by enhancing the transparency, reliability and users' trust in AI-driven fact-checking systems. Furthermore, the development of our metric learning models is a first step towards potentially increasing efficiency and reducing reliance on extensive manual assessment. Based on experimental results, our best performing generative model \textsc{ROUGE-1} score of 47.77, demonstrating superior performance in generating fact-checking explanations, particularly when provided with high-quality evidence. Additionally, the best performing metric learning model showed a moderately strong correlation with human judgements on objective dimensions such as \texttt{(self)-contradiction and \texttt{hallucination}, achieving a Matthews Correlation Coefficient (MCC) of around 0.7.}