 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models
Paper and Code
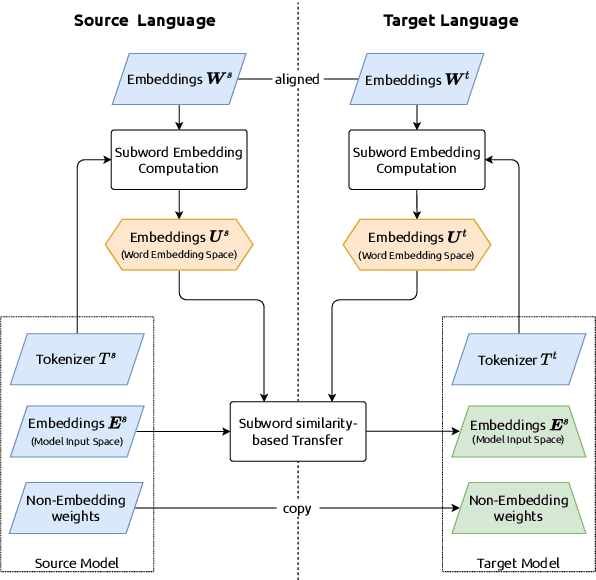
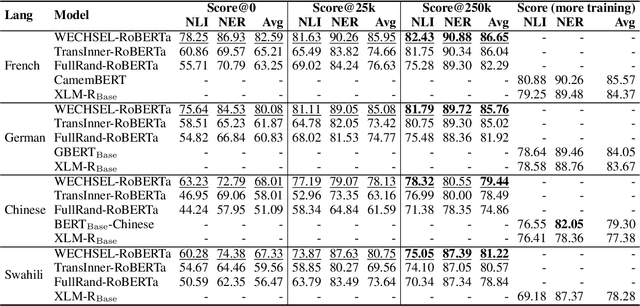
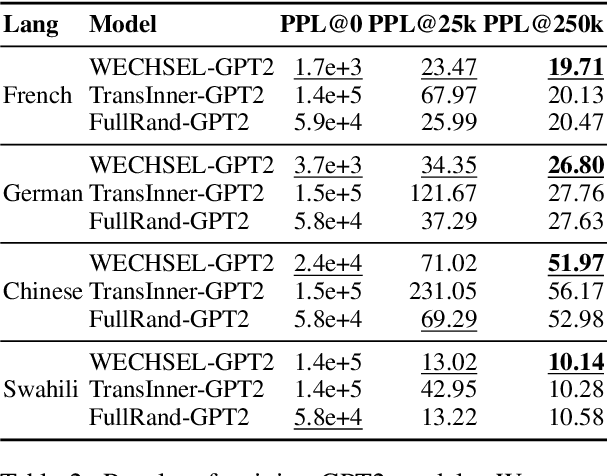
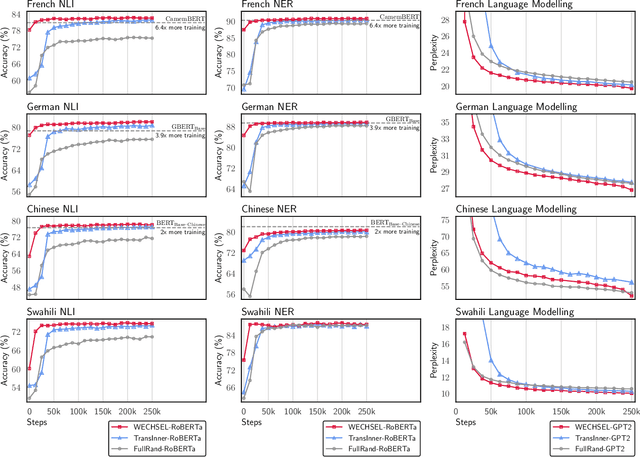
Recently, large pretrained language models (LMs) have gained popularity. Training these models requires ever more computational resources and most of the existing models are trained on English text only. It is exceedingly expensive to train these models in other languages. To alleviate this problem, we introduce a method -- called WECHSEL -- to transfer English models to new languages. We exchange the tokenizer of the English model with a tokenizer in the target language and initialize token embeddings such that they are close to semantically similar English tokens by utilizing multilingual static word embeddings covering English and the target language. We use WECHSEL to transfer GPT-2 and RoBERTa models to 4 other languages (French, German, Chinese and Swahili). WECHSEL improves over a previously proposed method for cross-lingual parameter transfer and outperforms models of comparable size trained from scratch in the target language with up to 64x less training effort. Our method makes training large language models for new languages more accessible and less damaging to the environment. We make our code and models publicly available.