 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncode-Store-Retrieve: Enhancing Memory Augmentation through Language-Encoded Egocentric Perception
Aug 10, 2023We depend on our own memory to encode, store, and retrieve our experiences. However, memory lapses can occur. One promising avenue for achieving memory augmentation is through the use of augmented reality head-mounted displays to capture and preserve egocentric videos, a practice commonly referred to as life logging. However, a significant challenge arises from the sheer volume of video data generated through life logging, as the current technology lacks the capability to encode and store such large amounts of data efficiently. Further, retrieving specific information from extensive video archives requires substantial computational power, further complicating the task of quickly accessing desired content. To address these challenges, we propose a memory augmentation system that involves leveraging natural language encoding for video data and storing them in a vector database. This approach harnesses the power of large vision language models to perform the language encoding process. Additionally, we propose using large language models to facilitate natural language querying. Our system underwent extensive evaluation using the QA-Ego4D dataset and achieved state-of-the-art results with a BLEU score of 8.3, outperforming conventional machine learning models that scored between 3.4 and 5.8. Additionally, in a user study, our system received a higher mean response score of 4.13/5 compared to the human participants' score of 2.46/5 on real-life episodic memory tasks.
The Imaginative Generative Adversarial Network: Automatic Data Augmentation for Dynamic Skeleton-Based Hand Gesture and Human Action Recognition
May 27, 2021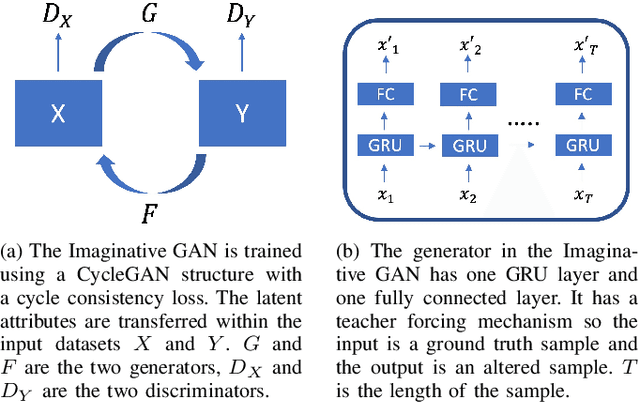
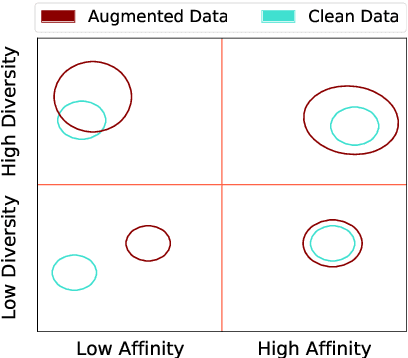
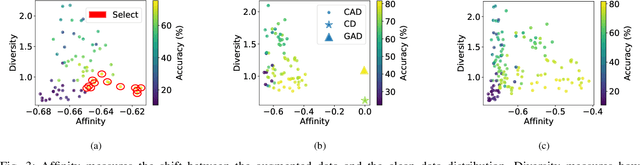
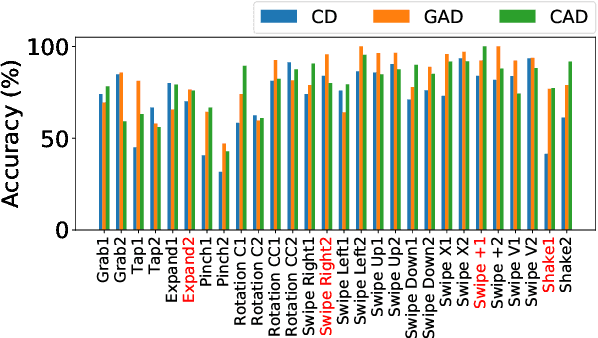
Deep learning approaches deliver state-of-the-art performance in recognition of spatiotemporal human motion data. However, one of the main challenges in these recognition tasks is limited available training data. Insufficient training data results in over-fitting and data augmentation is one approach to address this challenge. Existing data augmentation strategies, such as transformations including scaling, shifting and interpolating, require hyperparameter optimization that can easily cost hundreds of GPU hours. In this paper, we present a novel automatic data augmentation model, the Imaginative Generative Adversarial Network (GAN) that approximates the distribution of the input data and samples new data from this distribution. It is automatic in that it requires no data inspection and little hyperparameter tuning and therefore it is a low-cost and low-effort approach to generate synthetic data. The proposed data augmentation strategy is fast to train and the synthetic data leads to higher recognition accuracy than using data augmented with a classical approach.