 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Ask-Answer Network for Machine Reading Comprehension
Paper and Code
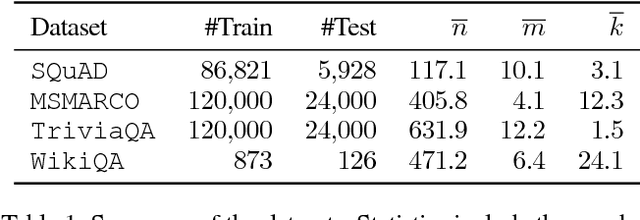
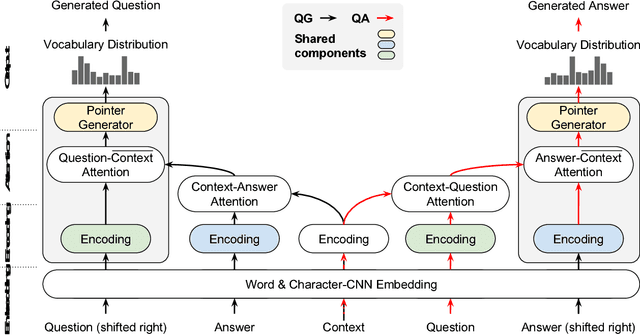
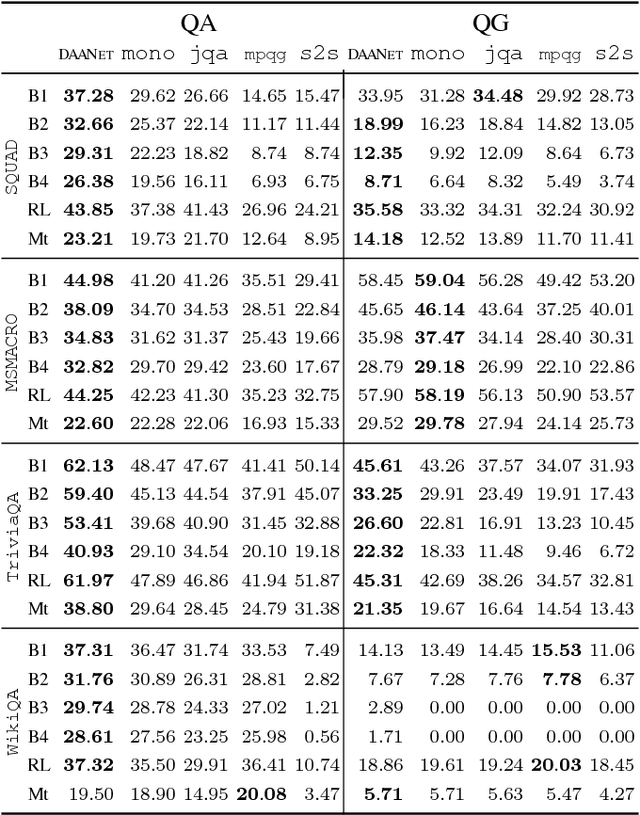
There are three modalities in the reading comprehension setting: question, answer and context. The task of question answering or question generation aims to infer an answer or a question when given the counterpart based on context. We present a novel two-way neural sequence transduction model that connects three modalities, allowing it to learn two tasks simultaneously and mutually benefit one another. During training, the model receives question-context-answer triplets as input and captures the cross-modal interaction via a hierarchical attention process. Unlike previous joint learning paradigms that leverage the duality of question generation and question answering at data level, we solve such dual tasks at the architecture level by mirroring the network structure and partially sharing components at different layers. This enables the knowledge to be transferred from one task to another, helping the model to find a general representation for each modality. The evaluation on four public datasets shows that our dual-learning model outperforms the mono-learning counterpart as well as the state-of-the-art joint models on both question answering and question generation tasks.