 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Domain Randomization for Sim-to-Real Transfer
Paper and Code
Mar 05, 2020
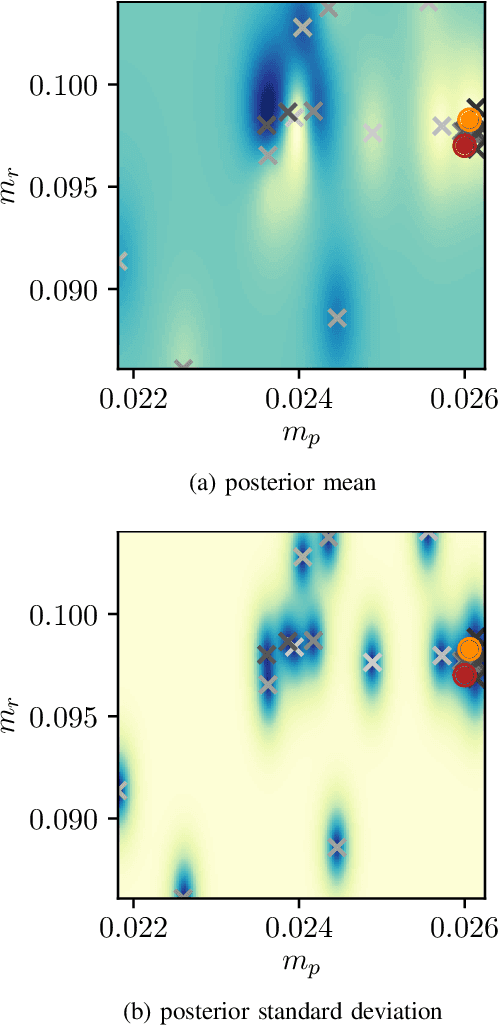
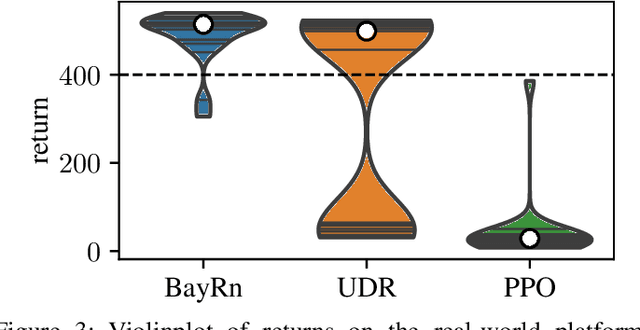
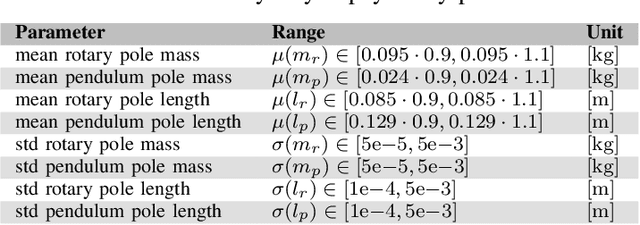
When learning policies for robot control, the real-world data required is typically prohibitively expensive to acquire, so learning in simulation is a popular strategy. Unfortunately, such polices are often not transferable to the real world due to a mismatch between the simulation and reality, called 'reality gap'. Domain randomization methods tackle this problem by randomizing the physics simulator (source domain) according to a distribution over domain parameters during training in order to obtain more robust policies that are able to overcome the reality gap. Most domain randomization approaches sample the domain parameters from a fixed distribution. This solution is suboptimal in the context of sim-to-real transferability, since it yields policies that have been trained without explicitly optimizing for the reward on the real system (target domain). Additionally, a fixed distribution assumes there is prior knowledge about the uncertainty over the domain parameters. Thus, we propose Bayesian Domain Randomization (BayRn), a black box sim-to-real algorithm that solves tasks efficiently by adapting the domain parameter distribution during learning by sampling the real-world target domain. BayRn utilizes Bayesian optimization to search the space of source domain distribution parameters which produce a policy that maximizes the real-word objective, allowing for adaptive distributions during policy optimization. We experimentally validate the proposed approach by comparing against two baseline methods on a nonlinear under-actuated swing-up task. Our results show that BayRn is capable to perform direct sim-to-real transfer, while significantly reducing the required prior knowledge.