 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT for Target Apps Selection: Analyzing the Diversity and Performance of BERT in Unified Mobile Search
Sep 13, 2021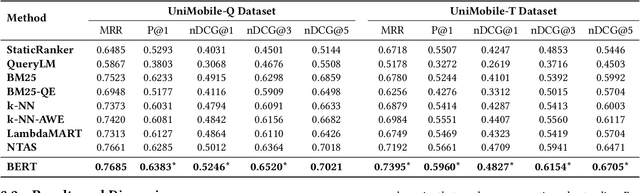
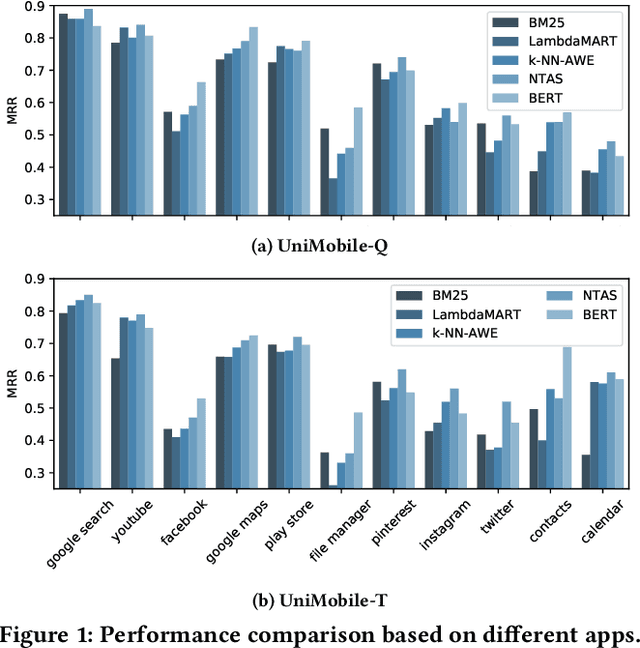
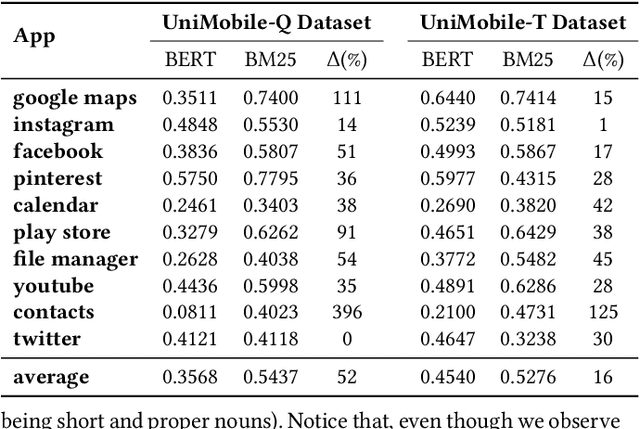
A unified mobile search framework aims to identify the mobile apps that can satisfy a user's information need and route the user's query to them. Previous work has shown that resource descriptions for mobile apps are sparse as they rely on the app's previous queries. This problem puts certain apps in dominance and leaves out the resource-scarce apps from the top ranks. In this case, we need a ranker that goes beyond simple lexical matching. Therefore, our goal is to study the extent of a BERT-based ranker's ability to improve the quality and diversity of app selection. To this end, we compare the results of the BERT-based ranker with other information retrieval models, focusing on the analysis of selected apps diversification. Our analysis shows that the BERT-based ranker selects more diverse apps while improving the quality of baseline results by selecting the relevant apps such as Facebook and Contacts for more personal queries and decreasing the bias towards the dominant resources such as the Google Search app.
Comparing Rule-based, Feature-based and Deep Neural Methods for De-identification of Dutch Medical Records
Jan 16, 2020
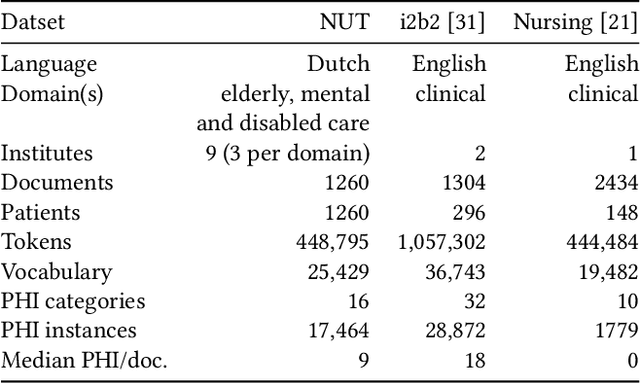
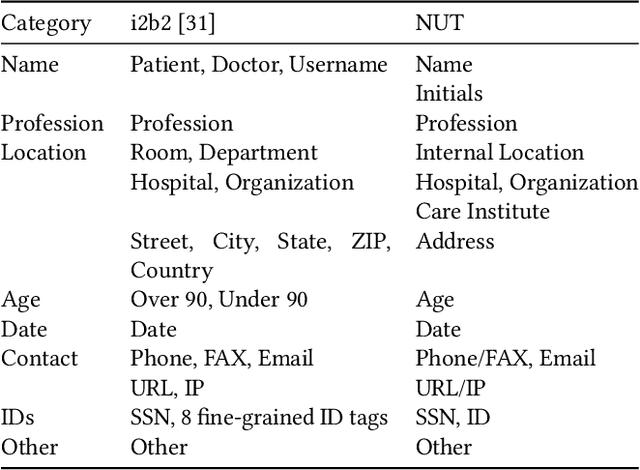
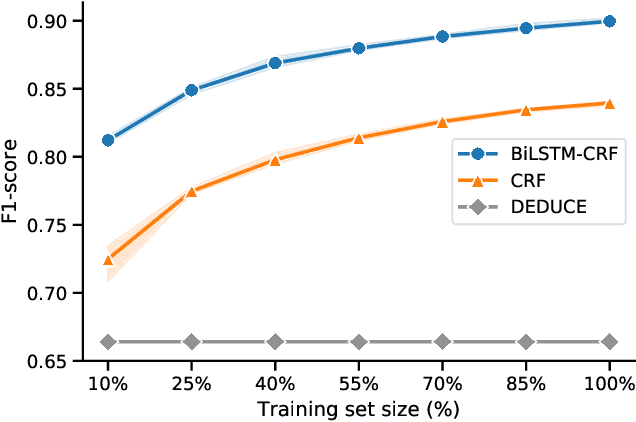
Unstructured information in electronic health records provide an invaluable resource for medical research. To protect the confidentiality of patients and to conform to privacy regulations, de-identification methods automatically remove personally identifying information from these medical records. However, due to the unavailability of labeled data, most existing research is constrained to English medical text and little is known about the generalizability of de-identification methods across languages and domains. In this study, we construct a varied dataset consisting of the medical records of 1260 patients by sampling data from 9 institutes and three domains of Dutch healthcare. We test the generalizability of three de-identification methods across languages and domains. Our experiments show that an existing rule-based method specifically developed for the Dutch language fails to generalize to this new data. Furthermore, a state-of-the-art neural architecture performs strongly across languages and domains, even with limited training data. Compared to feature-based and rule-based methods the neural method requires significantly less configuration effort and domain-knowledge. We make all code and pre-trained de-identification models available to the research community, allowing practitioners to apply them to their datasets and to enable future benchmarks.
Separate Training for Conditional Random Fields Using Co-occurrence Rate Factorization
Dec 04, 2012
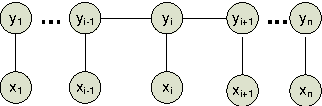
The standard training method of Conditional Random Fields (CRFs) is very slow for large-scale applications. As an alternative, piecewise training divides the full graph into pieces, trains them independently, and combines the learned weights at test time. In this paper, we present \emph{separate} training for undirected models based on the novel Co-occurrence Rate Factorization (CR-F). Separate training is a local training method. In contrast to MEMMs, separate training is unaffected by the label bias problem. Experiments show that separate training (i) is unaffected by the label bias problem; (ii) reduces the training time from weeks to seconds; and (iii) obtains competitive results to the standard and piecewise training on linear-chain CRFs.