 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAM: Relative Flatness Aware Minimization
Jul 05, 2023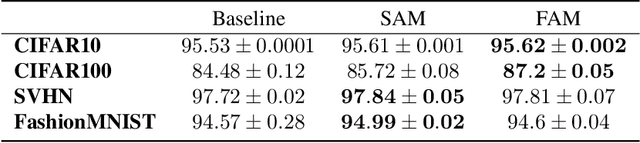
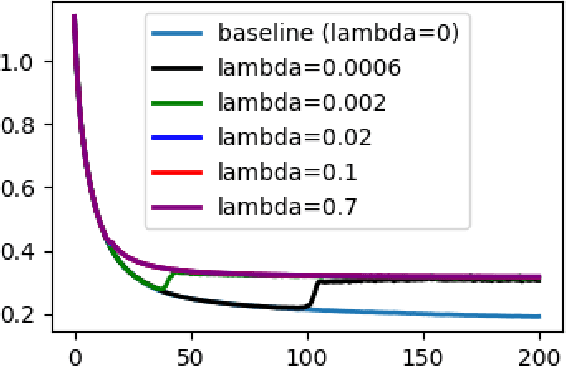
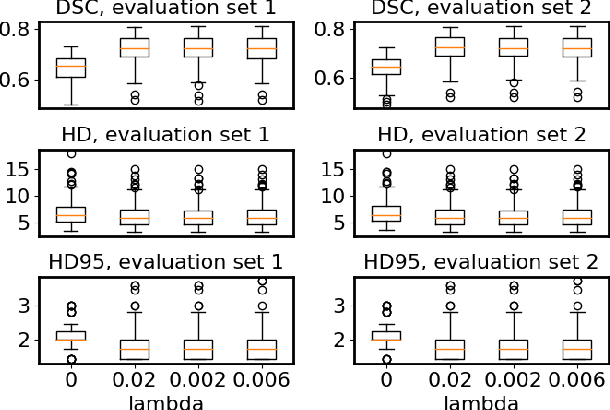

Flatness of the loss curve around a model at hand has been shown to empirically correlate with its generalization ability. Optimizing for flatness has been proposed as early as 1994 by Hochreiter and Schmidthuber, and was followed by more recent successful sharpness-aware optimization techniques. Their widespread adoption in practice, though, is dubious because of the lack of theoretically grounded connection between flatness and generalization, in particular in light of the reparameterization curse - certain reparameterizations of a neural network change most flatness measures but do not change generalization. Recent theoretical work suggests that a particular relative flatness measure can be connected to generalization and solves the reparameterization curse. In this paper, we derive a regularizer based on this relative flatness that is easy to compute, fast, efficient, and works with arbitrary loss functions. It requires computing the Hessian only of a single layer of the network, which makes it applicable to large neural networks, and with it avoids an expensive mapping of the loss surface in the vicinity of the model. In an extensive empirical evaluation we show that this relative flatness aware minimization (FAM) improves generalization in a multitude of applications and models, both in finetuning and standard training. We make the code available at github.
Discriminating Against Unrealistic Interpolations in Generative Adversarial Networks
Mar 02, 2022
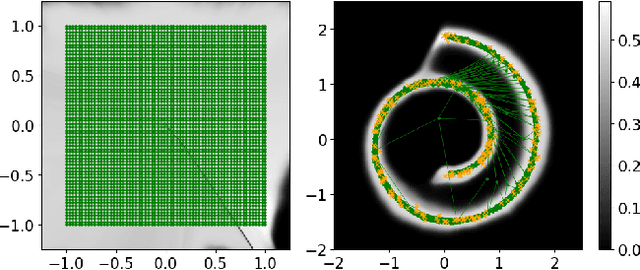
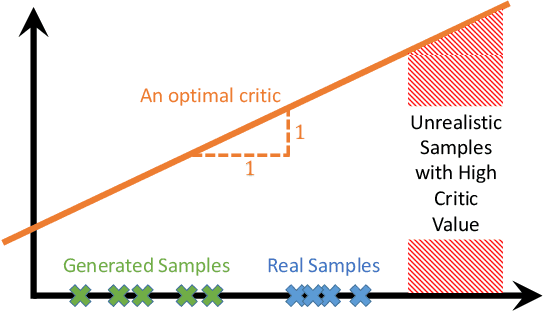
Interpolations in the latent space of deep generative models is one of the standard tools to synthesize semantically meaningful mixtures of generated samples. As the generator function is non-linear, commonly used linear interpolations in the latent space do not yield the shortest paths in the sample space, resulting in non-smooth interpolations. Recent work has therefore equipped the latent space with a suitable metric to enforce shortest paths on the manifold of generated samples. These are often, however, susceptible of veering away from the manifold of real samples, resulting in smooth but unrealistic generation that requires an additional method to assess the sample quality along paths. Generative Adversarial Networks (GANs), by construction, measure the sample quality using its discriminator network. In this paper, we establish that the discriminator can be used effectively to avoid regions of low sample quality along shortest paths. By reusing the discriminator network to modify the metric on the latent space, we propose a lightweight solution for improved interpolations in pre-trained GANs.
Feature-Robustness, Flatness and Generalization Error for Deep Neural Networks
Jan 07, 2020

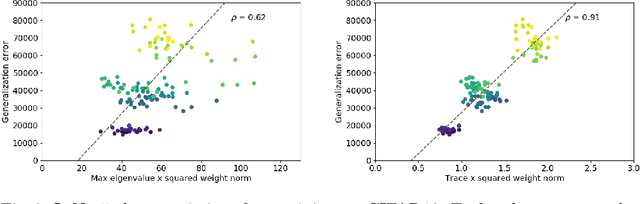

The performance of deep neural networks is often attributed to their automated, task-related feature construction. It remains an open question, though, why this leads to solutions with good generalization, even in cases where the number of parameters is larger than the number of samples. Back in the 90s, Hochreiter and Schmidhuber observed that flatness of the loss surface around a local minimum correlates with low generalization error. For several flatness measures, this correlation has been empirically validated. However, it has recently been shown that existing measures of flatness cannot theoretically be related to generalization: if a network uses ReLU activations, the network function can be reparameterized without changing its output in such a way that flatness is changed almost arbitrarily. This paper proposes a natural modification of existing flatness measures that results in invariance to reparameterization. The proposed measures imply a robustness of the network to changes in the input and the hidden layers. Connecting this feature robustness to generalization leads to a generalized definition of the representativeness of data. With this, the generalization error of a model trained on representative data can be bounded by its feature robustness which depends on our novel flatness measure.
A Reparameterization-Invariant Flatness Measure for Deep Neural Networks
Nov 29, 2019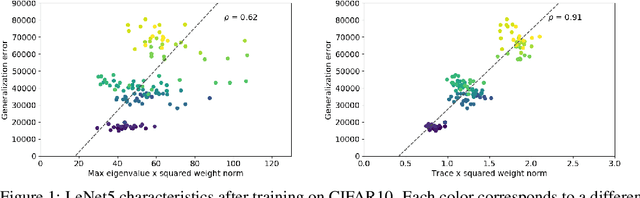

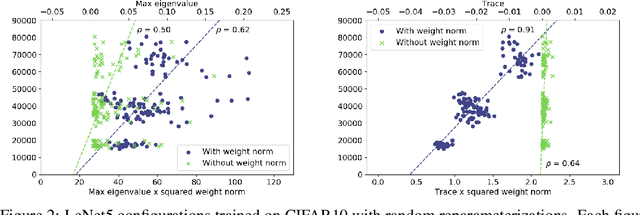
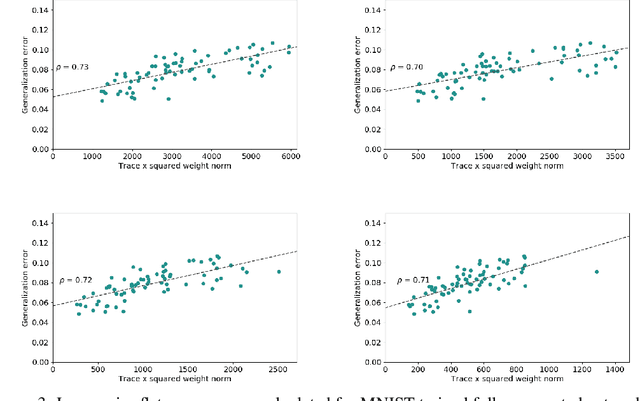
The performance of deep neural networks is often attributed to their automated, task-related feature construction. It remains an open question, though, why this leads to solutions with good generalization, even in cases where the number of parameters is larger than the number of samples. Back in the 90s, Hochreiter and Schmidhuber observed that flatness of the loss surface around a local minimum correlates with low generalization error. For several flatness measures, this correlation has been empirically validated. However, it has recently been shown that existing measures of flatness cannot theoretically be related to generalization due to a lack of invariance with respect to reparameterizations. We propose a natural modification of existing flatness measures that results in invariance to reparameterization.
Non-attracting Regions of Local Minima in Deep and Wide Neural Networks
Dec 18, 2018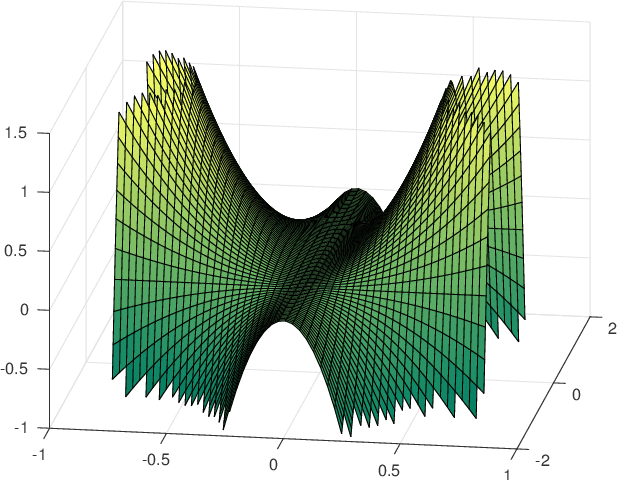
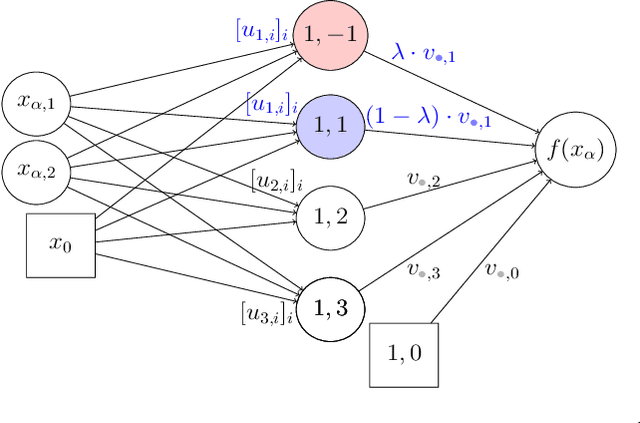
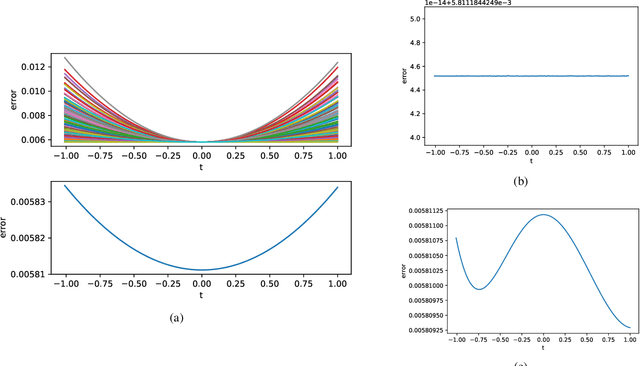
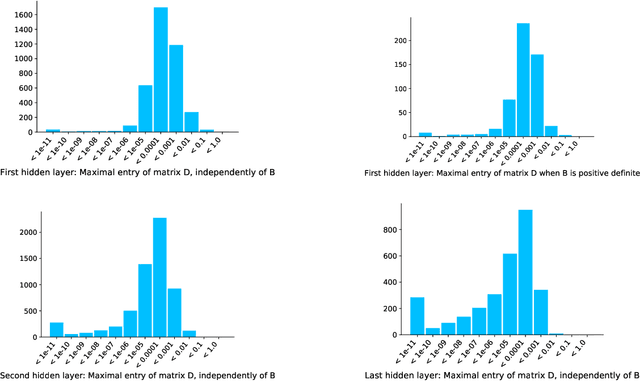
Understanding the loss surface of neural networks is essential for the design of models with predictable performance and their success in applications. Experimental results suggest that sufficiently deep and wide neural networks are not negatively impacted by suboptimal local minima. Despite recent progress, the reason for this outcome is not fully understood. Could deep networks have very few, if at all, suboptimal local optima? or could all of them be equally good? We provide a construction to show that suboptimal local minima (i.e. non-global ones), even though degenerate, exist for fully connected neural networks with sigmoid activation functions. The local minima obtained by our proposed construction belong to a connected set of local solutions that can be escaped from via a non-increasing path on the loss curve. For extremely wide neural networks with two hidden layers, we prove that every suboptimal local minimum belongs to such a connected set. This provides a partial explanation for the successful application of deep neural networks. In addition, we also characterize under what conditions the same construction leads to saddle points instead of local minima for deep neural networks.
On the regularization of Wasserstein GANs
Mar 05, 2018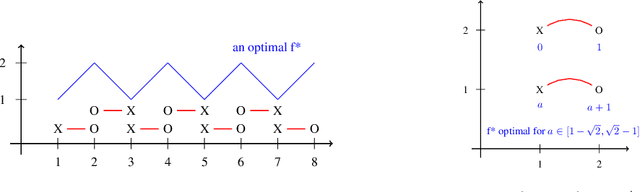
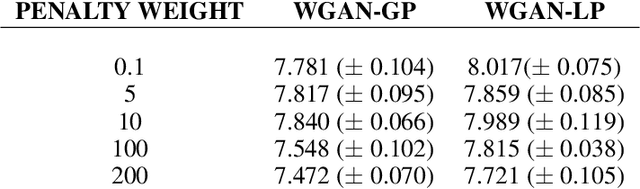

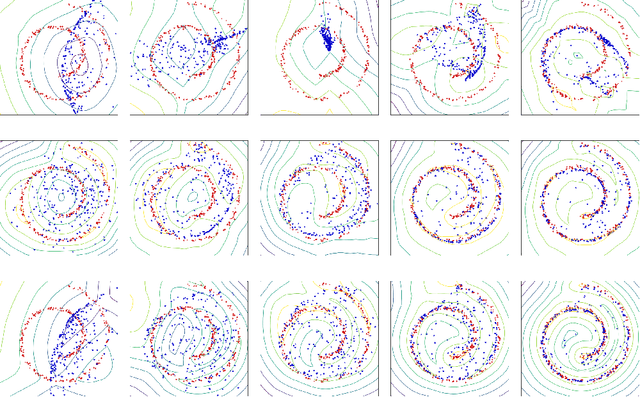
Since their invention, generative adversarial networks (GANs) have become a popular approach for learning to model a distribution of real (unlabeled) data. Convergence problems during training are overcome by Wasserstein GANs which minimize the distance between the model and the empirical distribution in terms of a different metric, but thereby introduce a Lipschitz constraint into the optimization problem. A simple way to enforce the Lipschitz constraint on the class of functions, which can be modeled by the neural network, is weight clipping. It was proposed that training can be improved by instead augmenting the loss by a regularization term that penalizes the deviation of the gradient of the critic (as a function of the network's input) from one. We present theoretical arguments why using a weaker regularization term enforcing the Lipschitz constraint is preferable. These arguments are supported by experimental results on toy data sets.