 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Audio Pattern Recognition for Asthma Medication Adherence: Evaluation with the RDA Benchmark Suite
Jun 01, 2022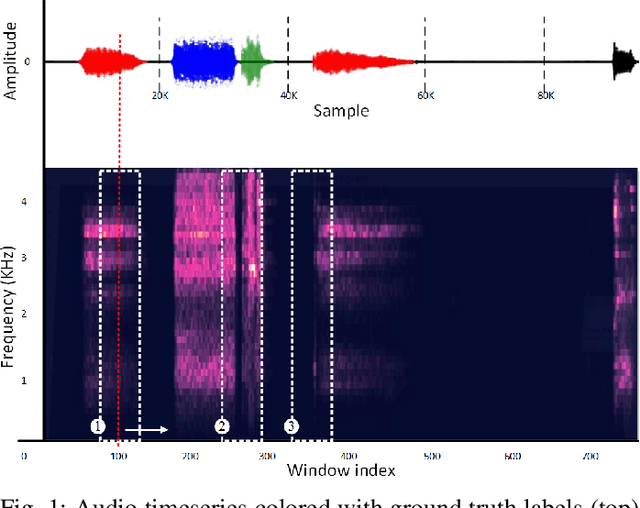
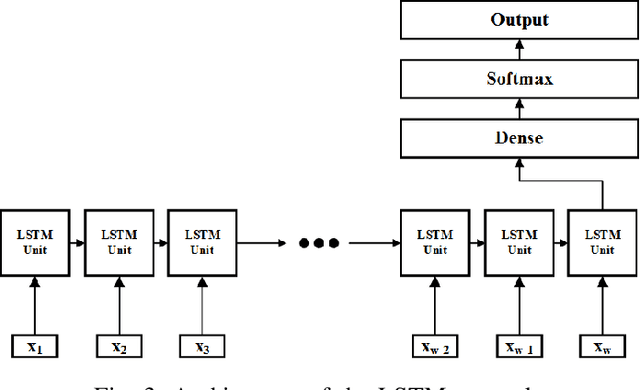
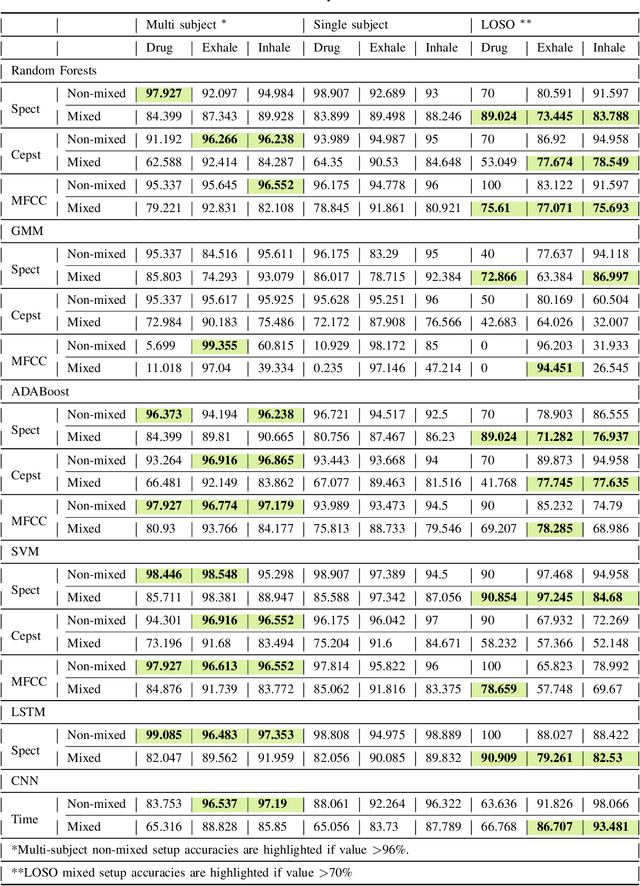
Asthma is a common, usually long-term respiratory disease with negative impact on society and the economy worldwide. Treatment involves using medical devices (inhalers) that distribute medication to the airways, and its efficiency depends on the precision of the inhalation technique. Health monitoring systems equipped with sensors and embedded with sound signal detection enable the recognition of drug actuation and could be powerful tools for reliable audio content analysis. This paper revisits audio pattern recognition and machine learning techniques for asthma medication adherence assessment and presents the Respiratory and Drug Actuation (RDA) Suite(https://gitlab.com/vvr/monitoring-medication-adherence/rda-benchmark) for benchmarking and further research. The RDA Suite includes a set of tools for audio processing, feature extraction and classification and is provided along with a dataset consisting of respiratory and drug actuation sounds. The classification models in RDA are implemented based on conventional and advanced machine learning and deep network architectures. This study provides a comparative evaluation of the implemented approaches, examines potential improvements and discusses challenges and future tendencies.
Incremental Construction of Compact Acyclic NFAs
Jan 04, 2002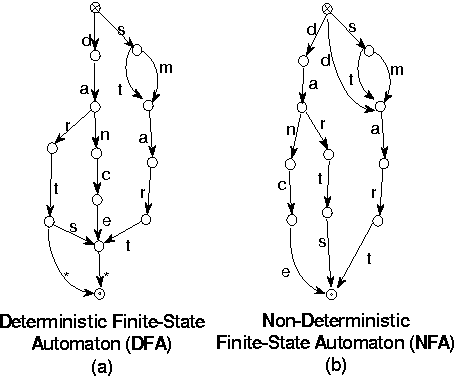

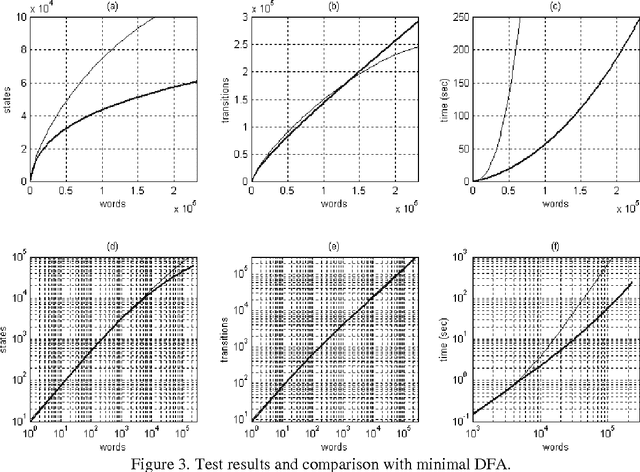
This paper presents and analyzes an incremental algorithm for the construction of Acyclic Non-deterministic Finite-state Automata (NFA). Automata of this type are quite useful in computational linguistics, especially for storing lexicons. The proposed algorithm produces compact NFAs, i.e. NFAs that do not contain equivalent states. Unlike Deterministic Finite-state Automata (DFA), this property is not sufficient to ensure minimality, but still the resulting NFAs are considerably smaller than the minimal DFAs for the same languages.
* 8(+2) pages, 4 figures, 1 table, 22 references. For related work, see also http://slt.wcl.ee.upatras.gr
A Straightforward Approach to Morphological Analysis and Synthesis
Dec 10, 2001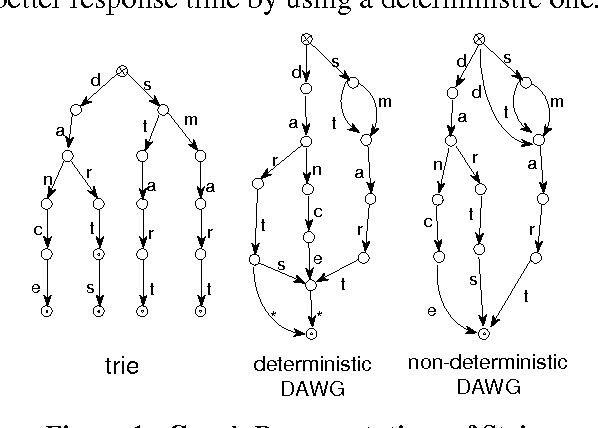
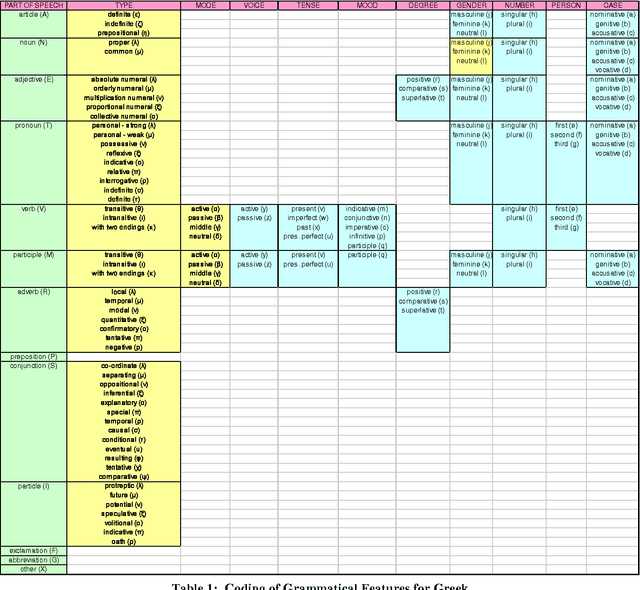
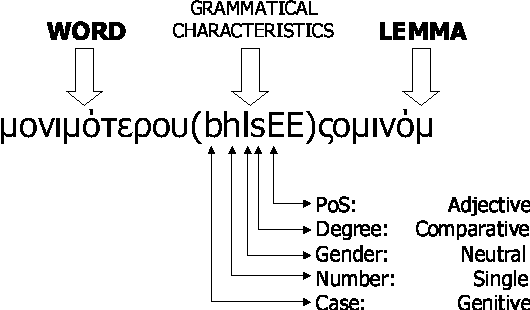
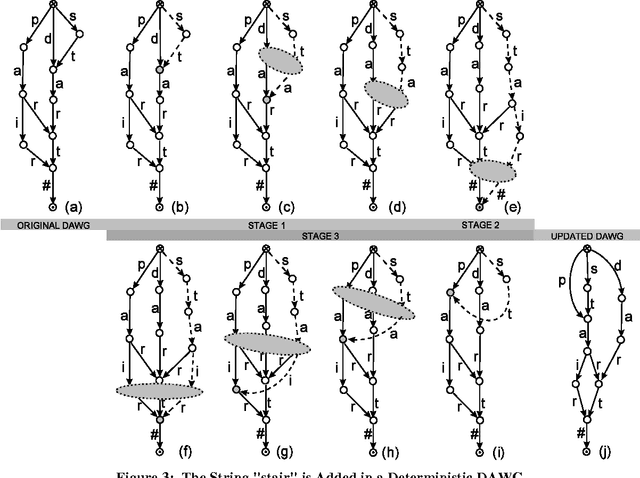
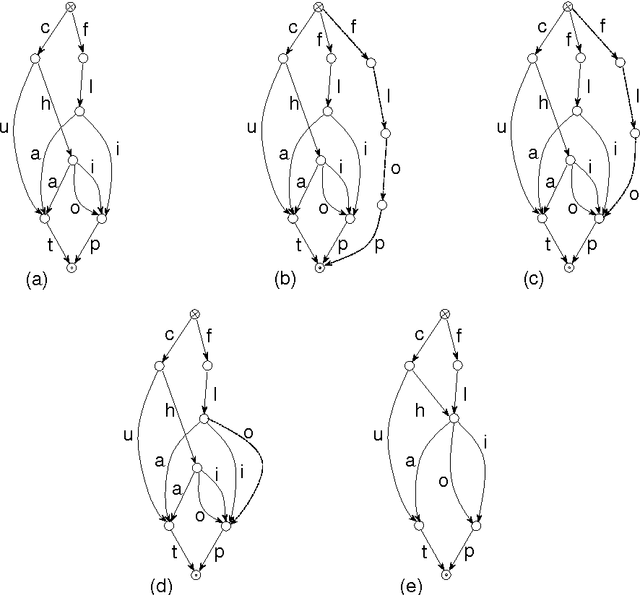
In this paper we present a lexicon-based approach to the problem of morphological processing. Full-form words, lemmas and grammatical tags are interconnected in a DAWG. Thus, the process of analysis/synthesis is reduced to a search in the graph, which is very fast and can be performed even if several pieces of information are missing from the input. The contents of the DAWG are updated using an on-line incremental process. The proposed approach is language independent and it does not utilize any morphophonetic rules or any other special linguistic information.
* 4(+2) pages, 3 figures, 1 table, 10 references. Keywords: Morphology, Directed Acyclic Word Graphs, Lexicon Structures. For related work, see also http://slt.wcl.ee.upatras.gr