 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPhD: Federated Pruning with Hierarchical Learning of Diffusion Models
Jul 08, 2025



Federated Learning (FL), as a distributed learning paradigm, trains models over distributed clients' data. FL is particularly beneficial for distributed training of Diffusion Models (DMs), which are high-quality image generators that require diverse data. However, challenges such as high communication costs and data heterogeneity persist in training DMs similar to training Transformers and Convolutional Neural Networks. Limited research has addressed these issues in FL environments. To address this gap and challenges, we introduce a novel approach, FedPhD, designed to efficiently train DMs in FL environments. FedPhD leverages Hierarchical FL with homogeneity-aware model aggregation and selection policy to tackle data heterogeneity while reducing communication costs. The distributed structured pruning of FedPhD enhances computational efficiency and reduces model storage requirements in clients. Our experiments across multiple datasets demonstrate that FedPhD achieves high model performance regarding Fr\'echet Inception Distance (FID) scores while reducing communication costs by up to $88\%$. FedPhD outperforms baseline methods achieving at least a $34\%$ improvement in FID, while utilizing only $56\%$ of the total computation and communication resources.
Decentralized Personalized Federated Learning based on a Conditional Sparse-to-Sparser Scheme
Apr 25, 2024

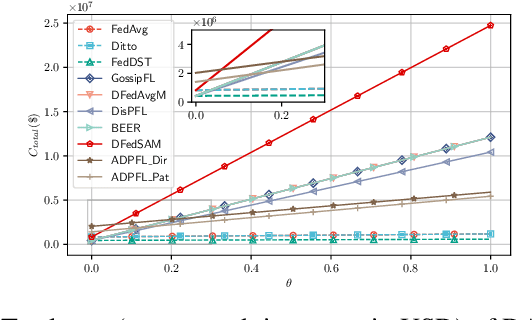

Decentralized Federated Learning (DFL) has become popular due to its robustness and avoidance of centralized coordination. In this paradigm, clients actively engage in training by exchanging models with their networked neighbors. However, DFL introduces increased costs in terms of training and communication. Existing methods focus on minimizing communication often overlooking training efficiency and data heterogeneity. To address this gap, we propose a novel \textit{sparse-to-sparser} training scheme: DA-DPFL. DA-DPFL initializes with a subset of model parameters, which progressively reduces during training via \textit{dynamic aggregation} and leads to substantial energy savings while retaining adequate information during critical learning periods. Our experiments showcase that DA-DPFL substantially outperforms DFL baselines in test accuracy, while achieving up to $5$ times reduction in energy costs. We provide a theoretical analysis of DA-DPFL's convergence by solidifying its applicability in decentralized and personalized learning. The code is available at:https://github.com/EricLoong/da-dpfl
FedDIP: Federated Learning with Extreme Dynamic Pruning and Incremental Regularization
Sep 13, 2023Federated Learning (FL) has been successfully adopted for distributed training and inference of large-scale Deep Neural Networks (DNNs). However, DNNs are characterized by an extremely large number of parameters, thus, yielding significant challenges in exchanging these parameters among distributed nodes and managing the memory. Although recent DNN compression methods (e.g., sparsification, pruning) tackle such challenges, they do not holistically consider an adaptively controlled reduction of parameter exchange while maintaining high accuracy levels. We, therefore, contribute with a novel FL framework (coined FedDIP), which combines (i) dynamic model pruning with error feedback to eliminate redundant information exchange, which contributes to significant performance improvement, with (ii) incremental regularization that can achieve \textit{extreme} sparsity of models. We provide convergence analysis of FedDIP and report on a comprehensive performance and comparative assessment against state-of-the-art methods using benchmark data sets and DNN models. Our results showcase that FedDIP not only controls the model sparsity but efficiently achieves similar or better performance compared to other model pruning methods adopting incremental regularization during distributed model training. The code is available at: https://github.com/EricLoong/feddip.