 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTR-Bench: Evaluating Geo-Temporal Reasoning in Vision-Language Models
Oct 09, 2025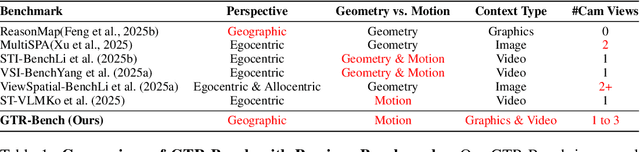
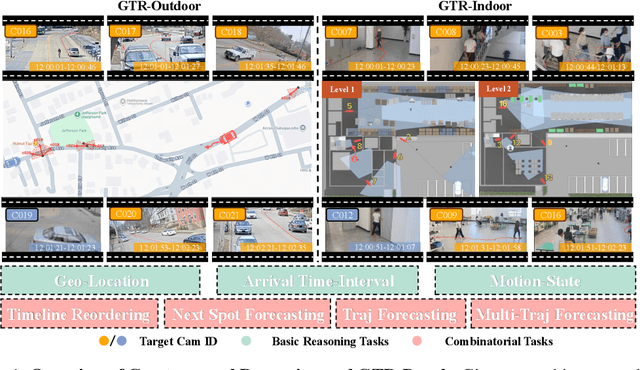
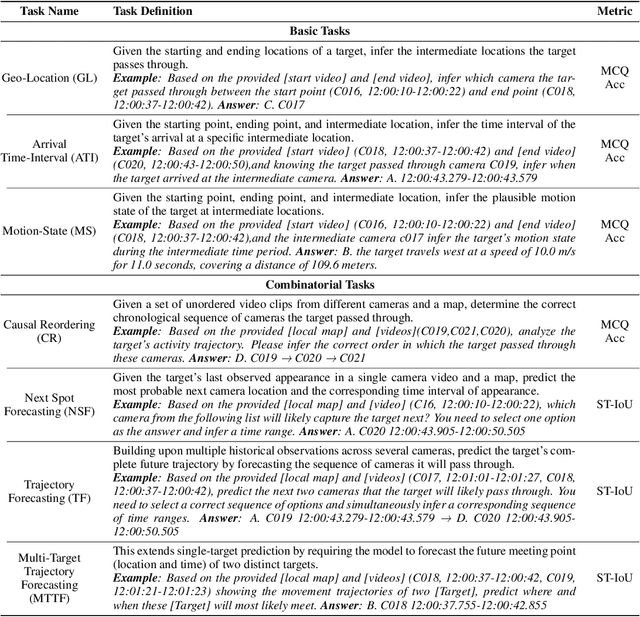
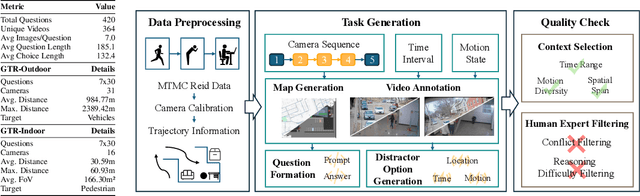
Recently spatial-temporal intelligence of Visual-Language Models (VLMs) has attracted much attention due to its importance for Autonomous Driving, Embodied AI and General Artificial Intelligence. Existing spatial-temporal benchmarks mainly focus on egocentric perspective reasoning with images/video context, or geographic perspective reasoning with graphics context (eg. a map), thus fail to assess VLMs' geographic spatial-temporal intelligence with both images/video and graphics context, which is important for areas like traffic management and emergency response. To address the gaps, we introduce Geo-Temporal Reasoning benchmark (GTR-Bench), a novel challenge for geographic temporal reasoning of moving targets in a large-scale camera network. GTR-Bench is more challenging as it requires multiple perspective switches between maps and videos, joint reasoning across multiple videos with non-overlapping fields of view, and inference over spatial-temporal regions that are unobserved by any video context. Evaluations of more than 10 popular VLMs on GTR-Bench demonstrate that even the best proprietary model, Gemini-2.5-Pro (34.9%), significantly lags behind human performance (78.61%) on geo-temporal reasoning. Moreover, our comprehensive analysis on GTR-Bench reveals three primary deficiencies of current models for geo-temporal reasoning. (1) VLMs' reasoning is impaired by an imbalanced utilization of spatial-temporal context. (2) VLMs are weak in temporal forecasting, which leads to worse performance on temporal-emphasized tasks than on spatial-emphasized tasks. (3) VLMs lack the proficiency to comprehend or align the map data with multi-view video inputs. We believe GTR-Bench offers valuable insights and opens up new opportunities for research and applications in spatial-temporal intelligence. Benchmark and code will be released at https://github.com/X-Luffy/GTR-Bench.
Embodied Intelligent Industrial Robotics: Concepts and Techniques
May 15, 2025In recent years, embodied intelligent robotics (EIR) has made significant progress in multi-modal perception, autonomous decision-making, and physical interaction. Some robots have already been tested in general-purpose scenarios such as homes and shopping malls. We aim to advance the research and application of embodied intelligence in industrial scenes. However, current EIR lacks a deep understanding of industrial environment semantics and the normative constraints between industrial operating objects. To address this gap, this paper first reviews the history of industrial robotics and the mainstream EIR frameworks. We then introduce the concept of the embodied intelligent industrial robotics (EIIR) and propose a knowledge-driven EIIR technology framework for industrial environments. The framework includes four main modules: world model, high-level task planner, low-level skill controller, and simulator. We also review the current development of technologies related to each module and highlight recent progress in adapting them to industrial applications. Finally, we summarize the key challenges EIIR faces in industrial scenarios and suggest future research directions. We believe that EIIR technology will shape the next generation of industrial robotics. Industrial systems based on embodied intelligent industrial robots offer strong potential for enabling intelligent manufacturing. We will continue to track and summarize new research in this area and hope this review will serve as a valuable reference for scholars and engineers interested in industrial embodied intelligence. Together, we can help drive the rapid advancement and application of this technology. The associated project can be found at https://github.com/jackyzengl/EIIR.
Demonstrating DVS: Dynamic Virtual-Real Simulation Platform for Mobile Robotic Tasks
Apr 26, 2025With the development of embodied artificial intelligence, robotic research has increasingly focused on complex tasks. Existing simulation platforms, however, are often limited to idealized environments, simple task scenarios and lack data interoperability. This restricts task decomposition and multi-task learning. Additionally, current simulation platforms face challenges in dynamic pedestrian modeling, scene editability, and synchronization between virtual and real assets. These limitations hinder real world robot deployment and feedback. To address these challenges, we propose DVS (Dynamic Virtual-Real Simulation Platform), a platform for dynamic virtual-real synchronization in mobile robotic tasks. DVS integrates a random pedestrian behavior modeling plugin and large-scale, customizable indoor scenes for generating annotated training datasets. It features an optical motion capture system, synchronizing object poses and coordinates between virtual and real world to support dynamic task benchmarking. Experimental validation shows that DVS supports tasks such as pedestrian trajectory prediction, robot path planning, and robotic arm grasping, with potential for both simulation and real world deployment. In this way, DVS represents more than just a versatile robotic platform; it paves the way for research in human intervention in robot execution tasks and real-time feedback algorithms in virtual-real fusion environments. More information about the simulation platform is available on https://immvlab.github.io/DVS/.
DSM: Building A Diverse Semantic Map for 3D Visual Grounding
Apr 11, 2025



In recent years, with the growing research and application of multimodal large language models (VLMs) in robotics, there has been an increasing trend of utilizing VLMs for robotic scene understanding tasks. Existing approaches that use VLMs for 3D Visual Grounding tasks often focus on obtaining scene information through geometric and visual information, overlooking the extraction of diverse semantic information from the scene and the understanding of rich implicit semantic attributes, such as appearance, physics, and affordance. The 3D scene graph, which combines geometry and language, is an ideal representation method for environmental perception and is an effective carrier for language models in 3D Visual Grounding tasks. To address these issues, we propose a diverse semantic map construction method specifically designed for robotic agents performing 3D Visual Grounding tasks. This method leverages VLMs to capture the latent semantic attributes and relations of objects within the scene and creates a Diverse Semantic Map (DSM) through a geometry sliding-window map construction strategy. We enhance the understanding of grounding information based on DSM and introduce a novel approach named DSM-Grounding. Experimental results show that our method outperforms current approaches in tasks like semantic segmentation and 3D Visual Grounding, particularly excelling in overall metrics compared to the state-of-the-art. In addition, we have deployed this method on robots to validate its effectiveness in navigation and grasping tasks.