 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajGen: Generating Realistic and Diverse Trajectories with Reactive and Feasible Agent Behaviors for Autonomous Driving
Mar 31, 2022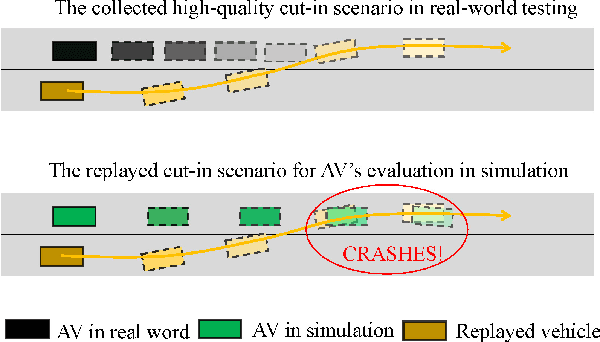
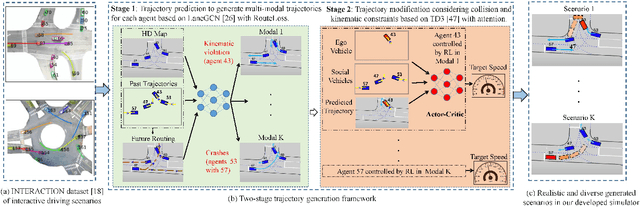
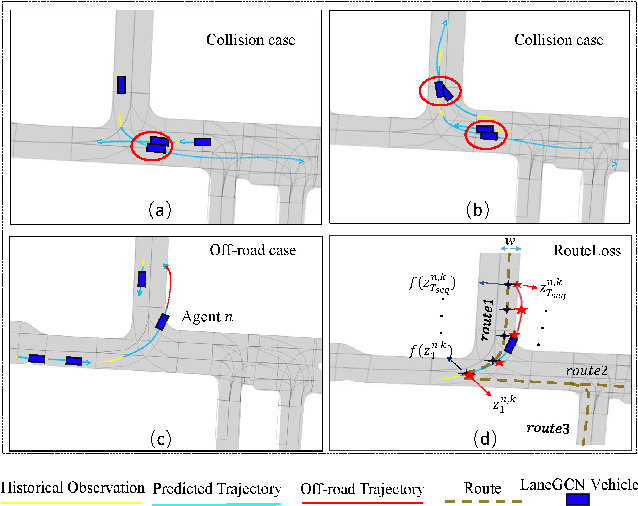
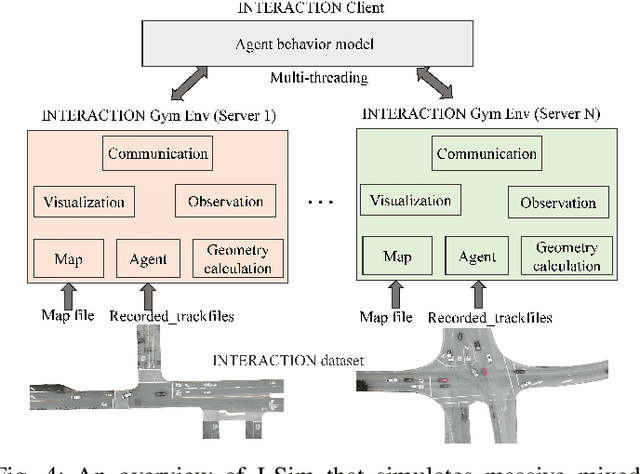
Realistic and diverse simulation scenarios with reactive and feasible agent behaviors can be used for validation and verification of self-driving system performance without relying on expensive and time-consuming real-world testing. Existing simulators rely on heuristic-based behavior models for background vehicles, which cannot capture the complex interactive behaviors in real-world scenarios. To bridge the gap between simulation and the real world, we propose TrajGen, a two-stage trajectory generation framework, which can capture more realistic behaviors directly from human demonstration. In particular, TrajGen consists of the multi-modal trajectory prediction stage and the reinforcement learning based trajectory modification stage. In the first stage, we propose a novel auxiliary RouteLoss for the trajectory prediction model to generate multi-modal diverse trajectories in the drivable area. In the second stage, reinforcement learning is used to track the predicted trajectories while avoiding collisions, which can improve the feasibility of generated trajectories. In addition, we develop a data-driven simulator I-Sim that can be used to train reinforcement learning models in parallel based on naturalistic driving data. The vehicle model in I-Sim can guarantee that the generated trajectories by TrajGen satisfy vehicle kinematic constraints. Finally, we give comprehensive metrics to evaluate generated trajectories for simulation scenarios, which shows that TrajGen outperforms either trajectory prediction or inverse reinforcement learning in terms of fidelity, reactivity, feasibility, and diversity.
Exploring More When It Needs in Deep Reinforcement Learning
Sep 28, 2021

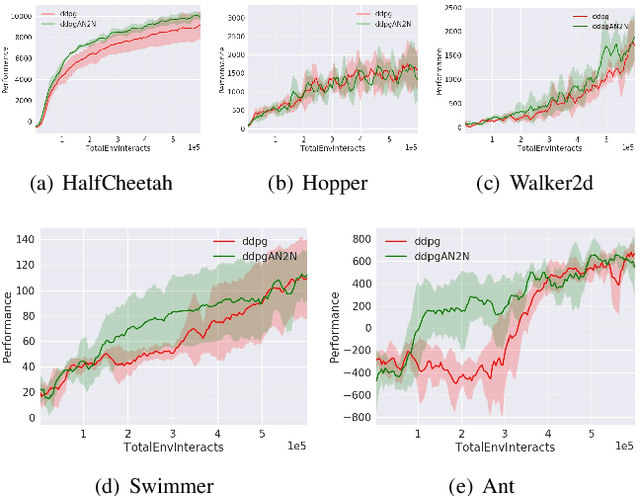

We propose a exploration mechanism of policy in Deep Reinforcement Learning, which is exploring more when agent needs, called Add Noise to Noise (AN2N). The core idea is: when the Deep Reinforcement Learning agent is in a state of poor performance in history, it needs to explore more. So we use cumulative rewards to evaluate which past states the agents have not performed well, and use cosine distance to measure whether the current state needs to be explored more. This method shows that the exploration mechanism of the agent's policy is conducive to efficient exploration. We combining the proposed exploration mechanism AN2N with Deep Deterministic Policy Gradient (DDPG), Soft Actor-Critic (SAC) algorithms, and apply it to the field of continuous control tasks, such as halfCheetah, Hopper, and Swimmer, achieving considerable improvement in performance and convergence speed.