 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Synthetic Images Serve as Effective and Efficient Class Prototypes?
Dec 19, 2025


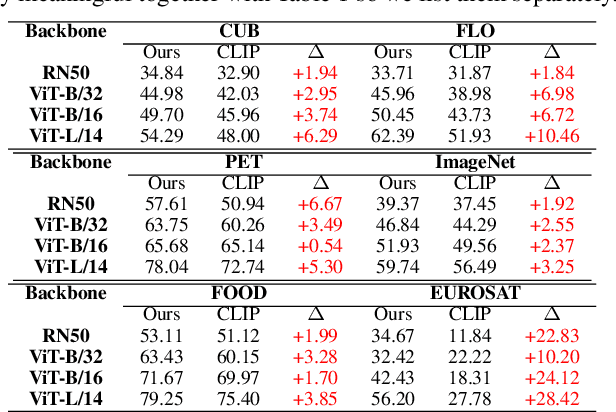
Vision-Language Models (VLMs) have shown strong performance in zero-shot image classification tasks. However, existing methods, including Contrastive Language-Image Pre-training (CLIP), all rely on annotated text-to-image pairs for aligning visual and textual modalities. This dependency introduces substantial cost and accuracy requirement in preparing high-quality datasets. At the same time, processing data from two modes also requires dual-tower encoders for most models, which also hinders their lightweight. To address these limitations, we introduce a ``Contrastive Language-Image Pre-training via Large-Language-Model-based Generation (LGCLIP)" framework. LGCLIP leverages a Large Language Model (LLM) to generate class-specific prompts that guide a diffusion model in synthesizing reference images. Afterwards these generated images serve as visual prototypes, and the visual features of real images are extracted and compared with the visual features of these prototypes to achieve comparative prediction. By optimizing prompt generation through the LLM and employing only a visual encoder, LGCLIP remains lightweight and efficient. Crucially, our framework requires only class labels as input during whole experimental procedure, eliminating the need for manually annotated image-text pairs and extra pre-processing. Experimental results validate the feasibility and efficiency of LGCLIP, demonstrating great performance in zero-shot classification tasks and establishing a novel paradigm for classification.
"You Are Rejected!": An Empirical Study of Large Language Models Taking Hiring Evaluations
Oct 22, 2025With the proliferation of the internet and the rapid advancement of Artificial Intelligence, leading technology companies face an urgent annual demand for a considerable number of software and algorithm engineers. To efficiently and effectively identify high-potential candidates from thousands of applicants, these firms have established a multi-stage selection process, which crucially includes a standardized hiring evaluation designed to assess job-specific competencies. Motivated by the demonstrated prowess of Large Language Models (LLMs) in coding and reasoning tasks, this paper investigates a critical question: Can LLMs successfully pass these hiring evaluations? To this end, we conduct a comprehensive examination of a widely used professional assessment questionnaire. We employ state-of-the-art LLMs to generate responses and subsequently evaluate their performance. Contrary to any prior expectation of LLMs being ideal engineers, our analysis reveals a significant inconsistency between the model-generated answers and the company-referenced solutions. Our empirical findings lead to a striking conclusion: All evaluated LLMs fails to pass the hiring evaluation.
GenZSL: Generative Zero-Shot Learning Via Inductive Variational Autoencoder
May 17, 2025Remarkable progress in zero-shot learning (ZSL) has been achieved using generative models. However, existing generative ZSL methods merely generate (imagine) the visual features from scratch guided by the strong class semantic vectors annotated by experts, resulting in suboptimal generative performance and limited scene generalization. To address these and advance ZSL, we propose an inductive variational autoencoder for generative zero-shot learning, dubbed GenZSL. Mimicking human-level concept learning, GenZSL operates by inducting new class samples from similar seen classes using weak class semantic vectors derived from target class names (i.e., CLIP text embedding). To ensure the generation of informative samples for training an effective ZSL classifier, our GenZSL incorporates two key strategies. Firstly, it employs class diversity promotion to enhance the diversity of class semantic vectors. Secondly, it utilizes target class-guided information boosting criteria to optimize the model. Extensive experiments conducted on three popular benchmark datasets showcase the superiority and potential of our GenZSL with significant efficacy and efficiency over f-VAEGAN, e.g., 24.7% performance gains and more than $60\times$ faster training speed on AWA2. Codes are available at https://github.com/shiming-chen/GenZSL.
Discriminative Image Generation with Diffusion Models for Zero-Shot Learning
Dec 23, 2024



Generative Zero-Shot Learning (ZSL) methods synthesize class-related features based on predefined class semantic prototypes, showcasing superior performance. However, this feature generation paradigm falls short of providing interpretable insights. In addition, existing approaches rely on semantic prototypes annotated by human experts, which exhibit a significant limitation in their scalability to generalized scenes. To overcome these deficiencies, a natural solution is to generate images for unseen classes using text prompts. To this end, We present DIG-ZSL, a novel Discriminative Image Generation framework for Zero-Shot Learning. Specifically, to ensure the generation of discriminative images for training an effective ZSL classifier, we learn a discriminative class token (DCT) for each unseen class under the guidance of a pre-trained category discrimination model (CDM). Harnessing DCTs, we can generate diverse and high-quality images, which serve as informative unseen samples for ZSL tasks. In this paper, the extensive experiments and visualizations on four datasets show that our DIG-ZSL: (1) generates diverse and high-quality images, (2) outperforms previous state-of-the-art nonhuman-annotated semantic prototype-based methods by a large margin, and (3) achieves comparable or better performance than baselines that leverage human-annotated semantic prototypes. The codes will be made available upon acceptance of the paper.
ZeroMamba: Exploring Visual State Space Model for Zero-Shot Learning
Aug 27, 2024Zero-shot learning (ZSL) aims to recognize unseen classes by transferring semantic knowledge from seen classes to unseen ones, guided by semantic information. To this end, existing works have demonstrated remarkable performance by utilizing global visual features from Convolutional Neural Networks (CNNs) or Vision Transformers (ViTs) for visual-semantic interactions. Due to the limited receptive fields of CNNs and the quadratic complexity of ViTs, however, these visual backbones achieve suboptimal visual-semantic interactions. In this paper, motivated by the visual state space model (i.e., Vision Mamba), which is capable of capturing long-range dependencies and modeling complex visual dynamics, we propose a parameter-efficient ZSL framework called ZeroMamba to advance ZSL. Our ZeroMamba comprises three key components: Semantic-aware Local Projection (SLP), Global Representation Learning (GRL), and Semantic Fusion (SeF). Specifically, SLP integrates semantic embeddings to map visual features to local semantic-related representations, while GRL encourages the model to learn global semantic representations. SeF combines these two semantic representations to enhance the discriminability of semantic features. We incorporate these designs into Vision Mamba, forming an end-to-end ZSL framework. As a result, the learned semantic representations are better suited for classification. Through extensive experiments on four prominent ZSL benchmarks, ZeroMamba demonstrates superior performance, significantly outperforming the state-of-the-art (i.e., CNN-based and ViT-based) methods under both conventional ZSL (CZSL) and generalized ZSL (GZSL) settings. Code is available at: https://anonymous.4open.science/r/ZeroMamba.