 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Unified Generation and Understanding Models Maintain Semantic Equivalence Across Different Output Modalities?
Feb 27, 2026Unified Multimodal Large Language Models (U-MLLMs) integrate understanding and generation within a single architecture. However, existing evaluations typically assess these capabilities separately, overlooking semantic equivalence, i.e., the ability to manifest consistent reasoning results regardless of the output modality. In this work, we investigate whether current U-MLLMs satisfy this premise. We observe that while models demonstrate robust textual reasoning, they fail to maintain semantic equivalence when required to render the same results in the image modality. To rigorously diagnose this discrepancy, we introduce VGUBench, a framework to decouple reasoning logic from generation fidelity. VGUBench comprises three diagnostic tasks: (1)Textual Generative Understanding, establishing a baseline for reasoning accuracy in textual response; (2)Visual Generative Understanding, evaluating the ability to generate visual responses that represent the correct answer; and (3)a Visual Rendering control task, which assesses the ability to directly render explicit visual descriptions into images without complex reasoning. Our evaluation reveals a significant disparity: despite strong performance in textual understanding and visual rendering, U-MLLMs exhibit a marked performance collapse when required to generate visual answers to questions. Furthermore, we find a negligible correlation between visual answering performance and basic rendering quality. These results suggest that the failure stems not from insufficient generation fidelity, but from a breakdown in cross-modal semantic alignment. We provide diagnostic insights to address this challenge in future Unified Generation and Understanding Models.
Unleashing MLLMs on the Edge: A Unified Framework for Cross-Modal ReID via Adaptive SVD Distillation
Feb 13, 2026Practical cloud-edge deployment of Cross-Modal Re-identification (CM-ReID) faces challenges due to maintaining a fragmented ecosystem of specialized cloud models for diverse modalities. While Multi-Modal Large Language Models (MLLMs) offer strong unification potential, existing approaches fail to adapt them into a single end-to-end backbone and lack effective knowledge distillation strategies for edge deployment. To address these limitations, we propose MLLMEmbed-ReID, a unified framework based on a powerful cloud-edge architecture. First, we adapt a foundational MLLM into a state-of-the-art cloud model. We leverage instruction-based prompting to guide the MLLM in generating a unified embedding space across RGB, infrared, sketch, and text modalities. This model is then trained efficiently with a hierarchical Low-Rank Adaptation finetuning (LoRA-SFT) strategy, optimized under a holistic cross-modal alignment objective. Second, to deploy its knowledge onto an edge-native student, we introduce a novel distillation strategy motivated by the low-rank property in the teacher's feature space. To prioritize essential information, this method employs a Principal Component Mapping loss, while relational structures are preserved via a Feature Relation loss. Our lightweight edge-based model achieves state-of-the-art performance on multiple visual CM-ReID benchmarks, while its cloud-based counterpart excels across all CM-ReID benchmarks. The MLLMEmbed-ReID framework thus presents a complete and effective solution for deploying unified MLLM-level intelligence on resource-constrained devices. The code and models will be open-sourced soon.
AGMA: Adaptive Gaussian Mixture Anchors for Prior-Guided Multimodal Human Trajectory Forecasting
Feb 04, 2026Human trajectory forecasting requires capturing the multimodal nature of pedestrian behavior. However, existing approaches suffer from prior misalignment. Their learned or fixed priors often fail to capture the full distribution of plausible futures, limiting both prediction accuracy and diversity. We theoretically establish that prediction error is lower-bounded by prior quality, making prior modeling a key performance bottleneck. Guided by this insight, we propose AGMA (Adaptive Gaussian Mixture Anchors), which constructs expressive priors through two stages: extracting diverse behavioral patterns from training data and distilling them into a scene-adaptive global prior for inference. Extensive experiments on ETH-UCY, Stanford Drone, and JRDB datasets demonstrate that AGMA achieves state-of-the-art performance, confirming the critical role of high-quality priors in trajectory forecasting.
Unified Multimodal Vessel Trajectory Prediction with Explainable Navigation Intention
Nov 18, 2025Vessel trajectory prediction is fundamental to intelligent maritime systems. Within this domain, short-term prediction of rapid behavioral changes in complex maritime environments has established multimodal trajectory prediction (MTP) as a promising research area. However, existing vessel MTP methods suffer from limited scenario applicability and insufficient explainability. To address these challenges, we propose a unified MTP framework incorporating explainable navigation intentions, which we classify into sustained and transient categories. Our method constructs sustained intention trees from historical trajectories and models dynamic transient intentions using a Conditional Variational Autoencoder (CVAE), while using a non-local attention mechanism to maintain global scenario consistency. Experiments on real Automatic Identification System (AIS) datasets demonstrates our method's broad applicability across diverse scenarios, achieving significant improvements in both ADE and FDE. Furthermore, our method improves explainability by explicitly revealing the navigational intentions underlying each predicted trajectory.
KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints
Oct 22, 2025Large Multimodal Models encode extensive factual knowledge in their pre-trained weights. However, its knowledge remains static and limited, unable to keep pace with real-world developments, which hinders continuous knowledge acquisition. Effective knowledge injection thus becomes critical, involving two goals: knowledge adaptation (injecting new knowledge) and knowledge retention (preserving old knowledge). Existing methods often struggle to learn new knowledge and suffer from catastrophic forgetting. To address this, we propose KORE, a synergistic method of KnOwledge-oRientEd augmentations and constraints for injecting new knowledge into large multimodal models while preserving old knowledge. Unlike general text or image data augmentation, KORE automatically converts individual knowledge items into structured and comprehensive knowledge to ensure that the model accurately learns new knowledge, enabling accurate adaptation. Meanwhile, KORE stores previous knowledge in the covariance matrix of LMM's linear layer activations and initializes the adapter by projecting the original weights into the matrix's null space, defining a fine-tuning direction that minimizes interference with previous knowledge, enabling powerful retention. Extensive experiments on various LMMs, including LLaVA-v1.5-7B, LLaVA-v1.5-13B, and Qwen2.5-VL-7B, show that KORE achieves superior new knowledge injection performance and effectively mitigates catastrophic forgetting.
Pedestrian Trajectory Prediction Based on Social Interactions Learning With Random Weights
Jan 13, 2025



Pedestrian trajectory prediction is a critical technology in the evolution of self-driving cars toward complete artificial intelligence. Over recent years, focusing on the trajectories of pedestrians to model their social interactions has surged with great interest in more accurate trajectory predictions. However, existing methods for modeling pedestrian social interactions rely on pre-defined rules, struggling to capture non-explicit social interactions. In this work, we propose a novel framework named DTGAN, which extends the application of Generative Adversarial Networks (GANs) to graph sequence data, with the primary objective of automatically capturing implicit social interactions and achieving precise predictions of pedestrian trajectory. DTGAN innovatively incorporates random weights within each graph to eliminate the need for pre-defined interaction rules. We further enhance the performance of DTGAN by exploring diverse task loss functions during adversarial training, which yields improvements of 16.7\% and 39.3\% on metrics ADE and FDE, respectively. The effectiveness and accuracy of our framework are verified on two public datasets. The experimental results show that our proposed DTGAN achieves superior performance and is well able to understand pedestrians' intentions.
RobWE: Robust Watermark Embedding for Personalized Federated Learning Model Ownership Protection
Feb 29, 2024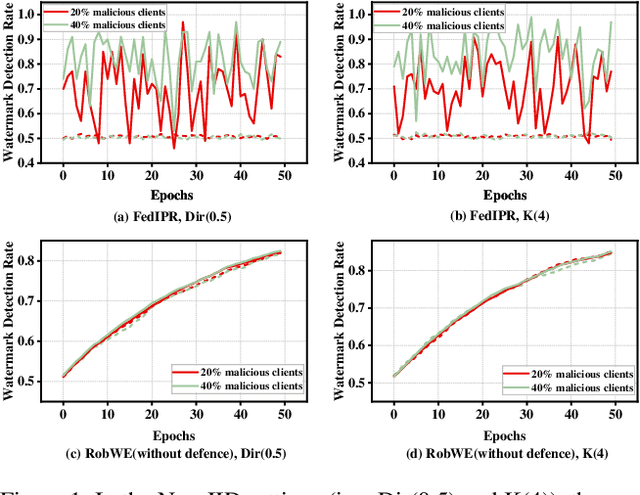



Embedding watermarks into models has been widely used to protect model ownership in federated learning (FL). However, existing methods are inadequate for protecting the ownership of personalized models acquired by clients in personalized FL (PFL). This is due to the aggregation of the global model in PFL, resulting in conflicts over clients' private watermarks. Moreover, malicious clients may tamper with embedded watermarks to facilitate model leakage and evade accountability. This paper presents a robust watermark embedding scheme, named RobWE, to protect the ownership of personalized models in PFL. We first decouple the watermark embedding of personalized models into two parts: head layer embedding and representation layer embedding. The head layer belongs to clients' private part without participating in model aggregation, while the representation layer is the shared part for aggregation. For representation layer embedding, we employ a watermark slice embedding operation, which avoids watermark embedding conflicts. Furthermore, we design a malicious watermark detection scheme enabling the server to verify the correctness of watermarks before aggregating local models. We conduct an exhaustive experimental evaluation of RobWE. The results demonstrate that RobWE significantly outperforms the state-of-the-art watermark embedding schemes in FL in terms of fidelity, reliability, and robustness.
Spatial-Temporal Conv-sequence Learning with Accident Encoding for Traffic Flow Prediction
May 21, 2021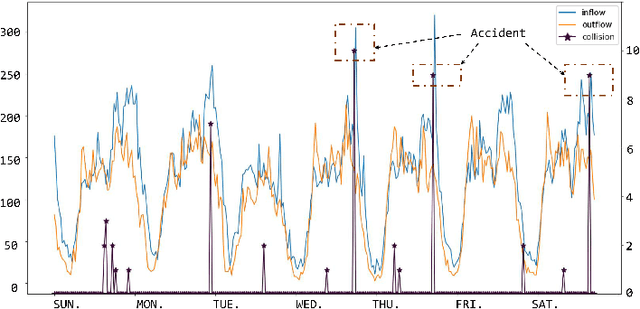
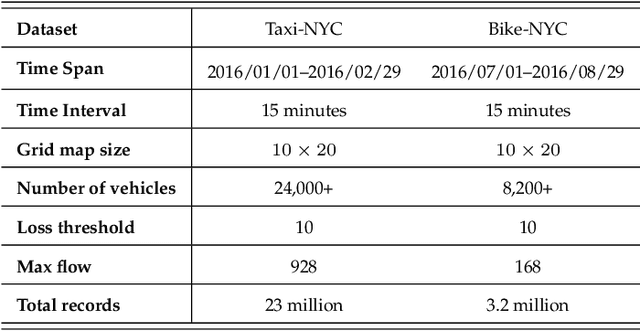
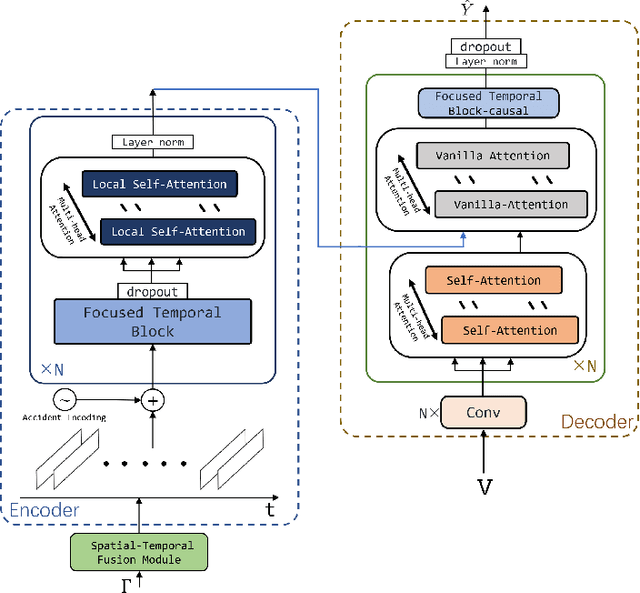
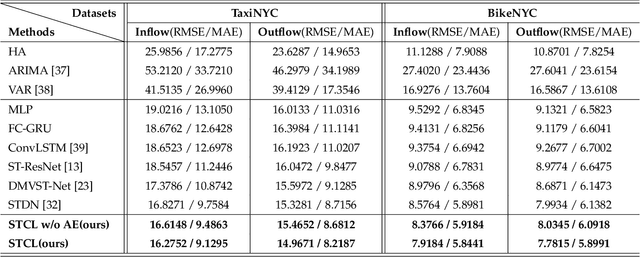
In intelligent transportation system, the key problem of traffic forecasting is how to extract the periodic temporal dependencies and complex spatial correlation. Current state-of-the-art methods for traffic flow prediction are based on graph architectures and sequence learning models, but they do not fully exploit spatial-temporal dynamic information in traffic system. Specifically, the temporal dependence of short-range is diluted by recurrent neural networks, and existing sequence model ignores local spatial information because the convolution operation uses global average pooling. Besides, there will be some traffic accidents during the transitions of objects causing congestion in the real world that trigger increased prediction deviation. To overcome these challenges, we propose the Spatial-Temporal Conv-sequence Learning (STCL), in which a focused temporal block uses unidirectional convolution to effectively capture short-term periodic temporal dependence, and a spatial-temporal fusion module is able to extract the dependencies of both interactions and decrease the feature dimensions. Moreover, the accidents features impact on local traffic congestion and position encoding is employed to detect anomalies in complex traffic situations. We conduct extensive experiments on large-scale real-world tasks and verify the effectiveness of our proposed method.
PURE: Passive mUlti-peRson idEntification via Deep Footstep Separation and Recognition
Apr 15, 2021
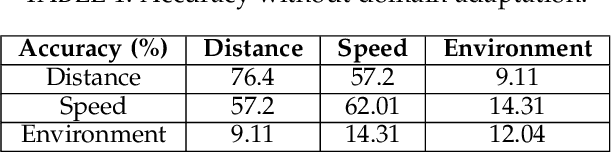
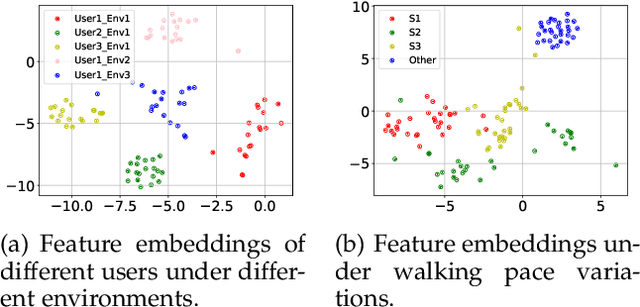
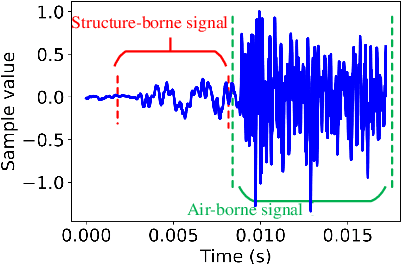
Recently, \textit{passive behavioral biometrics} (e.g., gesture or footstep) have become promising complements to conventional user identification methods (e.g., face or fingerprint) under special situations, yet existing sensing technologies require lengthy measurement traces and cannot identify multiple users at the same time. To this end, we propose \systemname\ as a passive multi-person identification system leveraging deep learning enabled footstep separation and recognition. \systemname\ passively identifies a user by deciphering the unique "footprints" in its footstep. Different from existing gait-enabled recognition systems incurring a long sensing delay to acquire many footsteps, \systemname\ can recognize a person by as few as only one step, substantially cutting the identification latency. To make \systemname\ adaptive to walking pace variations, environmental dynamics, and even unseen targets, we apply an adversarial learning technique to improve its domain generalisability and identification accuracy. Finally, \systemname\ can defend itself against replay attack, enabled by the richness of footstep and spatial awareness. We implement a \systemname\ prototype using commodity hardware and evaluate it in typical indoor settings. Evaluation results demonstrate a cross-domain identification accuracy of over 90\%.