 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTractable Local Equilibria in Non-Concave Games
Paper and Code
Mar 13, 2024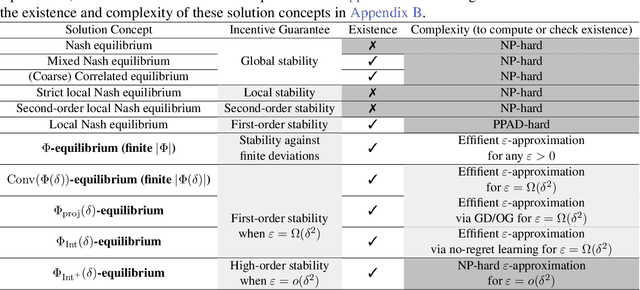
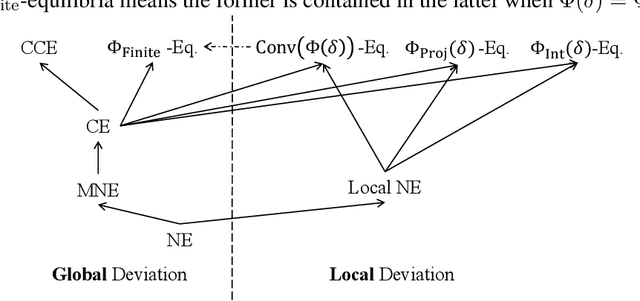
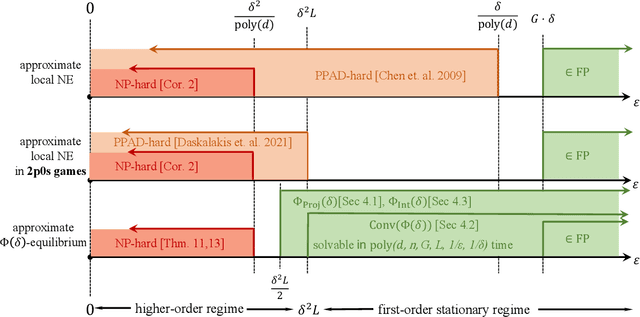
While Online Gradient Descent and other no-regret learning procedures are known to efficiently converge to coarse correlated equilibrium in games where each agent's utility is concave in their own strategy, this is not the case when the utilities are non-concave, a situation that is common in machine learning applications where the agents' strategies are parameterized by deep neural networks, or the agents' utilities are computed by a neural network, or both. Indeed, non-concave games present a host of game-theoretic and optimization challenges: (i) Nash equilibria may fail to exist; (ii) local Nash equilibria exist but are intractable; and (iii) mixed Nash, correlated, and coarse correlated equilibria have infinite support in general, and are intractable. To sidestep these challenges we propose a new solution concept, termed $(\varepsilon, \Phi(\delta))$-local equilibrium, which generalizes local Nash equilibrium in non-concave games, as well as (coarse) correlated equilibrium in concave games. Importantly, we show that two instantiations of this solution concept capture the convergence guarantees of Online Gradient Descent and no-regret learning, which we show efficiently converge to this type of equilibrium in non-concave games with smooth utilities.