 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Data Augmentation with Contrastive Learning
Paper and Code
Nov 07, 2023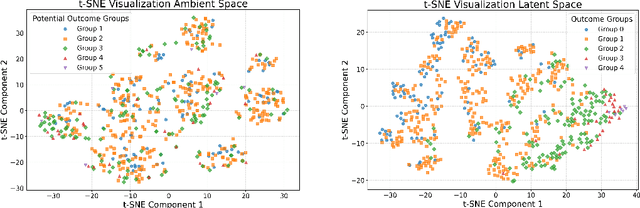
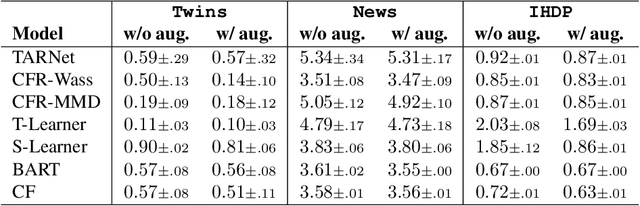

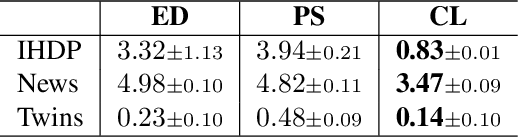
Statistical disparity between distinct treatment groups is one of the most significant challenges for estimating Conditional Average Treatment Effects (CATE). To address this, we introduce a model-agnostic data augmentation method that imputes the counterfactual outcomes for a selected subset of individuals. Specifically, we utilize contrastive learning to learn a representation space and a similarity measure such that in the learned representation space close individuals identified by the learned similarity measure have similar potential outcomes. This property ensures reliable imputation of counterfactual outcomes for the individuals with close neighbors from the alternative treatment group. By augmenting the original dataset with these reliable imputations, we can effectively reduce the discrepancy between different treatment groups, while inducing minimal imputation error. The augmented dataset is subsequently employed to train CATE estimation models. Theoretical analysis and experimental studies on synthetic and semi-synthetic benchmarks demonstrate that our method achieves significant improvements in both performance and robustness to overfitting across state-of-the-art models.